
Research:Recommending Images to Wikidata Items
Images allow to explain, enrich and complement knowledge without language barriers[1]. They can also help illustrate the content of an item in a language-agnostic way to external data consumers. However, a large proportion of Wikidata items lack images: for example, as of today, more than 3.6M Wikidata items are about humans (Q5) but only 17% of them have an image(sparql query). More in general, only 2.2M of 40 Million Wikidata items have an image attached. A wider presence of images in such a rich, cross-lingual repository enables a more complete representation of human knowledge.
We want to help Wikidata contributors make Wikidata more “visual” by recommending high-quality Commons images to Wikidata items.
Approach[edit]
We suggest a set of high-quality commons images for items where images are missing (could work potentially to replace low-quality images as well). This recommendation is be performed by a classifier able to (1) identify images relevant to a Wikidata entry (2) rank such images according to their visual quality.
More specifically, we propose to design first a matching system to evaluate the relevance of an image to a given item, based on usage, location, and contextual data. We will then design a computer vision-based classifier able to score relevant images in terms of quality based on the operationalisation of existing image quality guidelines [2][3]
Images in Wikidata[edit]
Wikidata catalogs a huge number of images, 2.5 millions, more than the total number of images in English Wikipedia. The number of visual contributions to Wikidata has grown massively in the past 3 years! However, 95% of wikidata items still lack images. While a large number of need might actually not need an image (e.g. bibliographic entries), some specific categories are in need of a visual representation. For example, only 17% of people items appear to have an image associated with them.
-
 Number of images in various Wiki projects
Number of images in various Wiki projects -
 percentage of Wikidata people items without images
percentage of Wikidata people items without images -
 percentage of Wikidata items without images
percentage of Wikidata items without images



Data Collection[edit]
- Image Subject Lists
- Monuments: all WikiData items Instances of Subclasses of Buildings having the property 'heritage designation' non empty
- People: all WikiData items Instances of humans
- Image Sources in other Wiki Projects: where can we find image candidates for items without P18 (image)?
- Images on Wikipedia Pages linked to an item (from globalimagelinks)
- Page Images on Wikipedia Pages linked to an item (from page_props)
- Pages resulting from free Commons Search from API
- Searching for Flickr Images:
- Images resulting from free text Search (query = entity name in all languages) using Flickr API, filtering for Creative Commons images only
- This also allows to discover how many images of this category match the one above: is there a way to include more CC images from Flickr in the commons for specific categories?
Data Analysis: Feasibility[edit]
To understand the extent to which the sources above actually contain potential image candidates, we ran 2 simple analysis experiments.
Monuments[edit]
- We took all entities of monuments and split them into With P18/Without P18, where P18 is the property field of Wikidata indicating the presence of an image describing the entity. Of around 100K entities, 2/3 have images and 1/3 don't.
- We then looked at how many pages are linked to each entity, and in which languages.. Only 20% of entities without images link to a Wikipedia page. In general, entities without an image link to pages in 2 or less different languages
- We then checked how many actual images lie in the linked pages: it is either 0 or more than 1
- We looked at how many Page Images are linked to entities, and this is similar to the page links number
- We counted the images returned by the commons free text search when queried with the entity name: here we find that around 50% of entities without images actually have at least one commons image matching them
- Finally, we counted the number of images in pages linked to the items, when images are not from commons (globalimagelinks) but attached within each wiki. We see that 20% of entities have Wiki image matching them
-
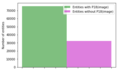 1 - Entities with/without images
1 - Entities with/without images -
 1 - Number of monument entities having l0,1,->10 linked pages
1 - Number of monument entities having l0,1,->10 linked pages -
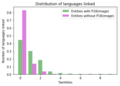 2 - Number of monument entities having linked images in 0,1,->10 languages
2 - Number of monument entities having linked images in 0,1,->10 languages -
 3 - Number of monument entities having 0,1,->10 commons images attached to pages linked
3 - Number of monument entities having 0,1,->10 commons images attached to pages linked -
 4 - Number of monument entities having 0,1,->10 linked page images
4 - Number of monument entities having 0,1,->10 linked page images -
 5 - Number of monument entities having 0,1,->10 commons images returned by when searching by entity name
5 - Number of monument entities having 0,1,->10 commons images returned by when searching by entity name -
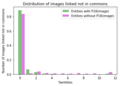 6 - Number of monuments entities having 0,1,->10 non-commons (in-wiki) images attached to pages linked
6 - Number of monuments entities having 0,1,->10 non-commons (in-wiki) images attached to pages linked
.png)
.png)
.png)
.png)
.png)
.png)
.png)
Overall, more than 60% of entities without an image have at least one image from one of the sources above, making this approach a viable solution to find image candidates to recommend to Wikidata items.
.png)
People[edit]
- We took all entities of people and split them into With P18/Without P18, where P18 is the property field of Wikidata indicating the presence of an image describing the entity. Of around 3.5M entities, 1/7 have images and the rest don't.
- We then looked at how many pages are linked to each entity, and in which languages.. Only 35% of entities without images do NOT link to a Wikipedia page. In general, entities without an image link to pages in 2 or less different languages (much less than entities with P18)
- We then checked how many actual images lie in the linked pages: in around 60% of the entities, more than 1 image can be found in linked pages
- We looked at how many Page Images are linked to entities: in this case, numbers are lower, only 30% of entities are linked to pages with page image specified
- We counted the images returned by the commons free text search when queried with the entity name: here we find that around 30% of entities without images actually have at least one commons image matching them
- Finally, we counted the number of images in pages linked to the items, when images are not from commons (globalimagelinks) but attached within each wiki. We see that more than 60% of entities have Wiki image matching them
-
 1 - Entities with/without images
1 - Entities with/without images -
 1 - Number of people entities having l0,1,->10 linked pages
1 - Number of people entities having l0,1,->10 linked pages -
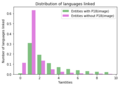 2 - Number of people entities having linked images in 0,1,->10 languages
2 - Number of people entities having linked images in 0,1,->10 languages -
 3 - Number of people entities having 0,1,->10 commons images attached to pages linked
3 - Number of people entities having 0,1,->10 commons images attached to pages linked -
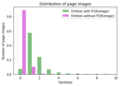 Number of people entities having 0-10 pages images linked (from wiki pages)
Number of people entities having 0-10 pages images linked (from wiki pages) -
 5 - Number of people entities having 0,1,->10 commons images returned by when searching by entity name
5 - Number of people entities having 0,1,->10 commons images returned by when searching by entity name -
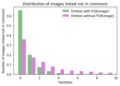 6 - Number of people entities having 0,1,->10 non-commons (in-wiki) images attached to pages linked
6 - Number of people entities having 0,1,->10 non-commons (in-wiki) images attached to pages linked
.png)
.png)
.png)
.png)
.png)
.png)
.png)
Overall, more than 70% of entities without an image have at least one image from one of the sources above, making this approach a viable solution to find image candidates to recommend to Wikidata items. Finding good images for this class of entities might also help identifying page images for biographies of people.
.png)
On Collecting Flickr Images[edit]
Here we look at whether Flickr is a good source for collecting CC images for Wikidata Items without an image attached.
Data Collection[edit]

We first look at the number of images returned by querying the Flickr search api with the following constraints
- They must have one of the following licences:
- 'CC-BY 2.0';
- 'CC-BY-SA 2.0';
- 'Public domain' ;
- 'U.S. Government' ;
- 'CC-0';
- 'Public Domain Mark' ;t
- They have to match the free text query corresponding to the entity label in any language
Results show that around 40% of entities without images have one or more matches in Flickr. In the plot below, we can see an artifact on the 10+ bin: it looks like a lot of entities have 10 or more images reteurned by the API. We still have to investigate why this number is so skewed, it might possibly be an artifact of the Flickr search API which returns results for more general query (general church instead of a specific church, for example). Indeed, while the total number of matches for 33K entities stands around 200K, this number boils down to only 35K when removing duplicates.
Detecting duplicates Commons/Flickr[edit]
When thinking about the possibility to use Flickr images for this project, one question arouse: what if Flickr CC images are already in the Commons? Checking for these kinds of duplicates does not narrow down to a simple url or title match. Possily, some information about the image source is available in the Commons description. This is not always the case. The safest way to do this is using a computer vision approach and check for exact (or semi-exact: we have to take into account resolution and compression artifacts) matches. We proceed as follows
- We download set C: all the Commons pictures returned by the previous experiment for monument entities without P18 specified.

typical convolutional neural network - We download set F: all the flickr images returing from the free text search above, for all entities of monuments without P18 specified.
- We want to represent all pictures in sets C and F with a unique signature. We do this by computing a visual feature summarizing the image content. More specifically, we extract the output of the second-last layer of a convolutional neural network (see picuture) called Inception-v3, trained to recognize objects in images at scale. Intuitively, the feature we extract from this network is a compact description of the image structure and content. This feature's dimension is 2048.
- We now want to compare features of set C to features of set F, and look for matches between the two sets. Since the 2048-d features are very high dimensional, we want to reduce their dimensionality in a way that the information needed to match images is preserved. Since we want to have semi-exact matches (to account for small modifications), we resort to Locality-sensitive hashing, a technique able to hash vectors so that similar vectors follow in the same bucket, to perform dimensionality reduction. We index the hash table with all images from set C, and then, for each image in F, look for the closest match in C. The algorithm returns a matching image and a similarity score s. To determine a threshold t for s below which we can trust the match (i.e. the match is real), we look at matched pairs at various thresholds.
- For t<5, the matches are 100% exact matches (exact duplicates): either we can see the FLickr image ID in the Commons title (e.g. :St_Dubricius,_Porlock_(2879499692).jpg) or, by visual inspection, we can see that, for example, that the file Church_cupolas_-_Nativity_of_the_Blessed_Virgin_Mary_Church.jpg matches the retrieved Flickr image with ID 36641532665

-
 Church_cupolas_-_Nativity_of_the_Blessed_Virgin_Mary_Church.jpg
Church_cupolas_-_Nativity_of_the_Blessed_Virgin_Mary_Church.jpg -
Church_cupolas_-_Nativity_of_the_Blessed_Virgin_Mary_Church.jpg

-
 Saint Matthews Church in the village of Morley in Derbyshire.
Saint Matthews Church in the village of Morley in Derbyshire. -
 Parish church Hoo St Werburgh - geograph.org.uk - 1624748
Parish church Hoo St Werburgh - geograph.org.uk - 1624748


- For thresholds greater than 30, the matching between F and C are wrong. Images still look structurally similar, but the content is different
-
 Chippenham Lodge 134
Chippenham Lodge 134 -
 This is Acocks Green Library on Shirley Road in Acocks Green Village.
This is Acocks Green Library on Shirley Road in Acocks Green Village.


.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
- In total, only 25 out of 33k matches have s<20 with their matches: this tells us that there is a lot to do in this direction, and there is an amazing opportunity to enriching Commons with Flickr data without repetitions starting from WikiData : 1) [automatic] for a wikidata item, retrieve set F and set C; 2) [automatic] match set F with set C; 3) [manual] add to WikiCommons those images from Flickr that are relevant to the item
Modeling Process[edit]
We developed a first prototype of a model able to retrieve images for wikidata items missing them. It works as follows.
- Define general categories of interest: for example, people, monuments, species, etc. Defining positive lists of items is important to a) scope the focus of the model b) target the recommendation
- Retrieve lists wikidata items belonging to the categories of interest. This process can be broken down into 2 pieces:
- Get property identifiers for wikidata. We want to retrieve only items with specific properties corresponding to the categories of interest. For example, all items of people are instance of property Q5 'human being'. While homogeneous categories (people) are characterised by one properties id only, heterogeneous categories such as monuments of species span multiple propertu identifiers. There are 2 ways to get these property ids in this case:
- Sparql query to get subclasses of the category of interest (e.g, [1])
- Find special identifiers for a given category (e.g. 'heritage designation' for monuments)
- Retrieve wikidata items instances of property identifiers: From the Json dumps, retain IDs and properties of wikidata items instances of (p31) the properties identified.
- Get property identifiers for wikidata. We want to retrieve only items with specific properties corresponding to the categories of interest. For example, all items of people are instance of property Q5 'human being'. While homogeneous categories (people) are characterised by one properties id only, heterogeneous categories such as monuments of species span multiple propertu identifiers. There are 2 ways to get these property ids in this case:
- - Collect images from pages linked to wikidata items retrieved, from the SQL Replicas.
- From the table of global links from entities to Wikipedia pages, we retrieve all pages linked to the wikidata items in the list. Then, we can collect two tipes of images:
- Images in pages From the table of global links from images to Wikipedia pages, we retrieve all images in the pages linked to the wikidata itmes in the list.
- Page Image From the table of page properties, we retrieve the 'page images' of the pages linked to the wikidata itmes in the list, namely the main image of each page.
- Collect images from Commons search. We use commons api to retrieve images from query = Wikidata item label (2.2), or query = page name (from 3.1)
- Build a quality model
- Build a deep learning model based on quality images using Tensorflow. This is done by finetuning a network initially trained to classify objects in imagenet. The model, given an image, gives as output a binary label (1:high quality; 0:low quality), together with a confidence score reflecting how trustable is the label in output. Accuracy on the test set stands at 72-73% Data for finetuning is built by:
- using as positive (high quality images) the Quality Commons Images.
- using as negative (low-quality images) random images from the commons.
- Extend model with complementary information as follows:
- Design basic features including image resolution and image description length (from sql replicas)
- Train a random forest classifier (5 trees) using as features: quality confidence score from (5.1); features in (5.2.1). Accuracy on the test set stands at 77-78%
- Build a deep learning model based on quality images using Tensorflow. This is done by finetuning a network initially trained to classify objects in imagenet. The model, given an image, gives as output a binary label (1:high quality; 0:low quality), together with a confidence score reflecting how trustable is the label in output. Accuracy on the test set stands at 72-73% Data for finetuning is built by:
- For a Wikidata item without an image, filter candidates by relevance
- Retain all images (3.2.3) and page images (3.2.3)
- Retain only those images retrieved from commons (4) whose image name soft matches (using fuzzy string match) the wikidata label OR the names of the pages linked to the item.
- Filter out images according to additional computer vision tools, depending on the category chosen
- For people: face detector
- For monuments: scene detectors [TODO possibly using pytorch with MITPlaces]
- sort images by quality
- download images filtered in 6
- assign quality score from 5
Results after filtering:
- 50K of 2.5M People Items, sample: https://meta.wikimedia.org/wiki/Research:Recommending_Images_to_Wikidata_Items/People_Retrieval_new
- 1.5K of 17 K Monument Items, sample: https://meta.wikimedia.org/wiki/Research:Recommending_Images_to_Wikidata_Items/Monument_Retrieval_new
bottlenecks:
- domain expertise for defining subclasses e.g. monuments
- visual processing is slow --> GPU?
- pixels are not available internally --> Create a folder on stats machine?
- not too many images available in Commons --> Extend to Flickr; Google; Others?
Evaluation[edit]
We want to get an early idea of the effectiveness of the ranking produced. To do so, we proceed as follows.
- We start from the Distributed Game platform. The Distribute Game allows Wikidata editors to select the right image for a Wikidata item, given a set of candidates.
- From historical records of the Distributed Game, we retrieve data for 66K items. For each item, we have the following information: item ID, candidate images, selected image (picture manually selected by the game players as the correct image for the item).
- We download all the candidate images for the 66K items, and run our algorithm.
- We then rank all candidates according to our algorithm and look at how the selected image is ranked.
- To do so, we employ a metric called en:Discounted_cumulative_gain#Normalized_DCG NDCG which measures how good the ranking produced by our algorithm is, by increasing the score every time the selected image is ranked in the top positions.
- Results show that our algorihtm, in 76% of the cases, is able to rank the selected image in the top 3. The plot below shows 2 versions of our algorithm: unsupervised (the one described above) and supervised (a supervised model based on decision trees combining relevance score - fuzzy match - and quality score)

Future Work[edit]
We will pilot a set of a recommendations (powered by tools like FIST platform) to evaluate if our machine learning method can help support community efforts to address the problem of missing images.[4]
Timeline[edit]
Q2,Q3
References[edit]
- ↑ Van Hook, S.R. (2011, 11 April). Modes and models for transcending cultural differences in international classrooms. Journal of Research in International Education, 10(1), 5-27. http://jri.sagepub.com/content/10/1/5
- ↑ https://commons.wikimedia.org/wiki/Commons:Image_guidelines
- ↑ https://commons.wikimedia.org/wiki/Commons:Quality_images_candidate
- ↑ FIST