
Wikimedia monthly activities meetings/Quarterly reviews/Parsoid, Services, MW Core, Ops, RelEng, MM, Labs and ECT, April 2015
Notes from the Quarterly Review meeting with the Wikimedia Foundation's Parsoid, Services, MediaWiki Core, Tech Ops, Release Engineering, Multimedia, Labs and Engineering Community teams, April 15, 2015, 9:30 - 11:00 PDT.
Please keep in mind that these minutes are mostly a rough transcript of what was said at the meeting, rather than a source of authoritative information. Consider referring to the presentation slides, blog posts, press releases and other official material
Present (in the office): Chris Steipp, Bryan Davis, Rob Lanphier, Terry Gilbey, Gabriel Wicke, Greg Grossmeier, Garfield Byrd, Erik Moeller, Lila Tretikov, Tilman Bayer (taking minutes); participating remotely: Gilles Dubuc, Subbu Sastry, Aaron Schulz, Andrew Bogott, Damon Sicore, Eric Evans, Faidon Liambotis, Geoff Brigham, Mark Bergsma, Marko Obrovac, Arlo Breault, Quim Gil, Chad Horohoe

Bryan: welcome
Parsoid[edit]
[slide 2]
Subbu:
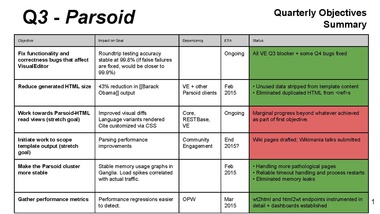
had 2 main goals, both for VE: fixes for VE, reduce HTML size
the next 2 goals are long-term: Parsoid HTML for readers, scope template output
Lila: the top two are important achievements, thanks!
For last two, define baseline, what is improvement delta
--> Action from Lila: set a target, define a baseline for Parsoid stability and performance improvements
Lila: What is the expected benefit from the template work?
Subbu: 1. significant performance improvements and reduced load on cluster
2. WYSIWYG in VE more reliable
RobLa: one of those simplifications in wikitext that will make it vastly easier to treat it in VE
Lila: but editors can still add content as before?
Gabriel, Subbu: (explanation)
--> Lila: talk about this [template long-term work] separately, may want to clean up some templates beforehand
RobLa: figure out how to work with community on this huge nasty engineering problem
--> Lila: should have a vision in mind; output of this for next q should be a design document on how future of templates should evolve in next 24 months
Subbu (PS after meeting): Given the nature of templates and their complexity, it will be difficult to produce a final plan by end of Q4 about what should happen and how this should evolve. We will likely have to prototype some ideas, consult, and experiment a bit before knowing how this will all shape up. That said, we can produce a draft about how to evolve templates that can help guide further action with the understanding that the ideas themselves might evolve and change. We can clarify this at the time we talk about this separately as Lila indicated, but just want to make sure that we have realistic expectations about this.

[slide 3]
successes
testing infrastructure: robust, but identified one hole when migrating VE to RESTbase, but fixed quickly
Terry: .... [?]
Subbu: did a good job earlier, but neglected it in last two quarters, this quarter we are going to work on it some more
Terry: if there are resource requirements, make sure they are recorded for next year's AP
Lila: also, figure out how standardized our infrastructure is
--> Action from Lila and Terry: make sure test infrastructure for Parsoid is in the budget

[slide 4]
misses
(Subbu:)
long tail is a problem
fixing wikitext / template processing model
Terry: considering the underspending in Engineering, I challenge you to consider adding capacity instead of scaling down [in such a situation].
Services[edit]
[slide 5]
Gabriel:
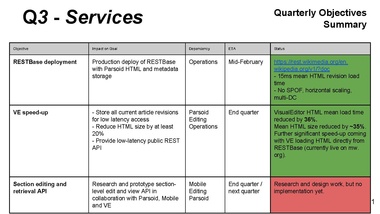
we focused on VE too
previously had caching setup where misses were very expensive
rolled out one or two weeks[?] later than planned, but good enough
We are storing basically everything now (all revisions)
Lila: cache hit rate before?
Gabriel: we had a very low hit rate before, now we're close to 100%.
Managed to reduce the html size by converting html to json blob that can be loaded separately.
Researched section editing API, no implementation yet

[slide 6]
successes
Better than expected:
RESTBase performance. 10k requests per second. High volume apps can now use this without killing our infrastructure.
API documentation was very well received.
Streamlined the development and deployment of internal services. Service template that many including our mobile apps team is using. standards for testing, metric collection and logging. Helping the Citoid and Graphoid service development
Still lot of work needed on pipeline

[slide 7]
Challenges:
Gabriel: section API work didn't get done
Lila: any progress on that?
Gabriel: planning, but nothing implemented
Helping other teams build services has been very valuable for them, but ties up our time
Lila: see the subject of shared infrastructure come up repeatedly
who manages that?
Greg: divided between several teams
Lila: does that make sense?
Greg: ideally not, but we are talking about ca. 30 people here
--> ACTION: Lila: should talk about responsibility for shared infrastructure, seems there's some inefficiency
Gabriel: speaking to that point, deployments take a lot of time
used to be one-off projects, now more routine
--> ACTION: Lila: for future reviews, can we add $ or number of people to template?
Terry: can do team size, $ will take more time
Garfield: can work on $ too
MediaWiki Core[edit]
[slide 8]
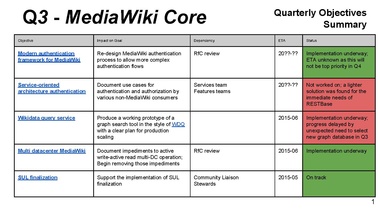
Bryan: redesign of authentication framework
Lila: (question about which authentication framework(s) are used currently)
Bryan, Chris: it's all homegrown
OAuth is just for external tools
Bryan: OAuth is the service wrapper around internal mechanism
now going through implementation of RfC
Lila: list of use cases?
Bryan: was planned, did not get done (I was repurposed as PM)
do have list of needed changes on PHP side
including things Chris wants for security
RobLa: context - at beginning of quarter, we thought it would be essential for RESTBase
talking to Gabriel, we found out we could cover the main use case with a simpler solution
rest is about e.g. password security[?]. Lead: Bryan Davis, API: Brad Jorsch
Lila: we should spend more time on figuring out requirements beforehand, uses case
how large is the team?
Bryan: in Q3 it was 8
Lila: this should be built to last, think about where we'll be in 5 years
RobLa: auth service was prerequisite for other planned things (that we wanted to do right now)
Bryan: WDQ (Wikidata Query Service; came out of WikiGrok originally)
make better use of Dallas data center
Lila: so this is a spec of how it should look like? yes
Bryan: big blockers e.g. remove unnecessary db read/writes
RobLa: it was more a lot of papercuts than a grand rewrite
Lila: reduce switchover from one hour to (a much shorter time)
Bryan: in our Q4 goals [on mw.org], have much more specific objectives

[slide 9]
successes
inter-team communications improved

[slide 10]
misses
Operations[edit]
[slide 11]
Mark (Bergsma):
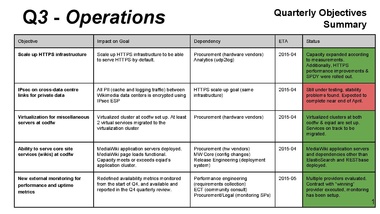
HTTPS work brought unplanned perf improvements
Terry: great
Lila: does Comms know about encryption work?
Mark: not specifically
--> Lila: ping Comms about encryption work (IPSec etc.)
Lila: assume virt cluster is going to be a long-running project
can we get a sense of its size? (e.g. 1000 machines)
and spell out the benefits
Mark: this is more for one-offs, e.g. Phabricator, monitoring
all things that are relatively small, not a lot of traffic, but currently consume a whole machine each
90%[?] of services could run on that
not a goal for next q, but part of ongoing work
leave existing services running, but when there's a maintenance case, consider switching them to virtual machine
Terry: expected life for existing hardware?
Mark: varies, 4-5 year in practice
Faidon: we don't commit everything, want to have extra capacity
Terry: do we pay maintenance on servers?
Garfield: 3 years, then longer if Mark wants
Mark: app servers are at capacity now
Erik: this is a big deal. If Ashburn goes down, we can switch over now?
Mark: yes, but some services might not be fully replicate yet
Lila: how quickly can things come back up?
Mark: several hours to get most functionality up
Lila: how long to get English WP back in read-only mode?
Mark: maybe in one hour (haven't tested)
but e.g would not have search
for partial outage...
not perfect yet
Lila: planning ...?
Mark: yes, but wait for MW Core to make it smoother
also, can't have it as goal becuase there's supposed to be only one per quarter
Erik: to recognize this, we have been operating without failover capacity for a year or so, big achievement
--> Terry: make list of what wouldn't come up in case of complete Ashburn outage
Mark: improved monitoring (on Lila's request)
Lila: yay :)

[slide 12]
sucesses

[slide 13]
misses
(Mark:)
IPsec: several engineers tied up with other things, and some upstream bugs
virt cluster: procurement took longer than it should have
Release Engineering[edit]
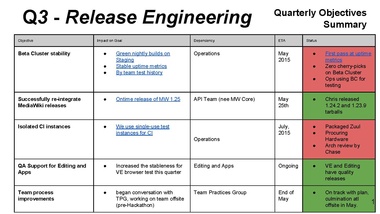
[slide 14]
Greg:
decided to redo beta cluster from scratch to make it more stable
(came out of volunteer project some years ago)
a lot of Puppet code cleanup
that took a lot longer than planned
hopefully done in May
Damon: difference between beta cluster and WMF Labs?
Greg: see "labs labs labs" wiki page https://wikitech.wikimedia.org/wiki/Labs_labs_labs
Bryan: Beta cluster runs within labs
Greg: (draws diagram)
this is completely separate from production
Beta cluster updates from master every 10 minutes
Bryan: it's running the prerelease code
Damon: dependency was?
Greg: Ops, e.g. we don't have root
Bryan: also, by skillset
Greg: it was a good dependency
Yuvi was a star, did great work
Bryan: basically it was bad scoping; didn't know how much it would take
Lila: how many VMs?
Bryan: 20-25 for beta cluster
Greg: 99% uptime in last few weeks (data we have)
mostly due to general labs downtime
Isolating CI instances: big project
should have been broken into smaller chunks
in progress, good working relationship
Lila: again, think about goals and outcomes
speed of deployment and testing?
Greg: yes
Erik: we wanted this for a long time
currently everything competes for testing resources
Bryan, Greg: this was Antoine
Terry: what if Antoine isn't available?
Greg: things would slow down
we would need to hire replacement, but have (some competency in other engineers)
-->[?] Lila: think about capacity of RelEng team in general
Greg: RelEng is force multiplier
currently 9, but 2 are manual testers, 2 are automated testing gurus
so 5 between deploy/ release/etc.
[slide 15]
successes

[slide 16]
misses
Multimedia[edit]
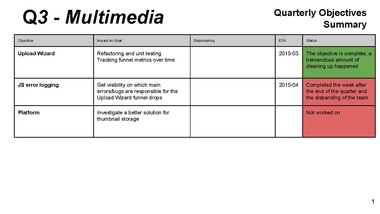
[slide 17]
Gilles: Mark H worked on Upload Wizard (known as one of the worst JavaScript parts in our code)
we tried to make that code quality improvement measurable, but this would have been too much work
dropoff rate is so high that we worry that it has technical reasons (client-side errors)
Erik: JS error logging will help with a ton of other projects as well
currently we are completely blind in that area
also, we give volunteers a lot of leeway in creating JS addons...
Sentry is an open source industry standard
[slide 18]
Gilles:
successes

[slide 19]
misses
lesson learned: with lots of fires to put out, logging goal with just one person was way too ambitious
Damon: examples for fires?
Gilles: e.g. UW stopped working altogether
some still unexplained, e.g. possibly connected with HHVM
thumbnails in some sizes stopped working
Damon: got it, thanks
Labs[edit]
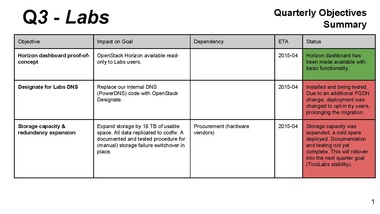
[slide 20]
Mark B:
Horizon - relatively limited in scope
DNS (Designate) mostly completed, deployed but we made it opt-in

[slide 21]
successes

[slide 22]
misses
unplanned distactions, e.g.:
major security issue (during dev summit)
hardware problems on two machines (these are somewhat older: 4 years)
this is always difficult (would be too on e.g. AWS)
don't have uptime metrics for Labs yet
Garfield: anything keeping us from 3 year cycle?
Mark: usually machines work longer than that, and replacing takes work time
that wasn't typical for most of our hardware
we won't have support after 3y, but usually have enough spare components to fix them ourselves
Engineering Community[edit]

[slide 23]
Quim:
context: earlier, much of team tied up by Phabricator migration, and dev summit preparation. We agreed to take it a bit easier during this quarter.
MediaWiki Developer Summit: success, with some things to improve.
Data and Developer Hub: didn't succed on delivering plan with stakeholders' approvals, but built a prototype
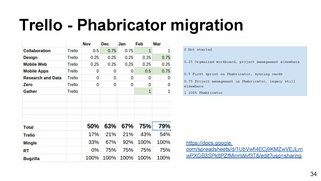
Phab migration (from Trello etc.): did not push migration, rely on force of tide instead. This proved right - trend is clear, it's just a matter of time.
Engage with established tech communities: delayed again, affected by lack of WMF vision.
Looking forward to working on this with new Partnerships team, already started talking.
--> Lila: need top-level KPIs for ECT, eg.:
- number of devs engaged/contributing code
- number of patches submitted/accepted
statistics like that
Quim: exactly this is one of our goals for the April-June quarter.
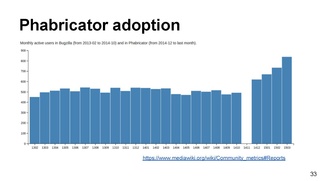
This time we only have metrics for Phabricator use, in the Appendix

[slide 24]
Successes
Earlier events had lots of informal feedback, or surveys that took a lot of time to process, but for the first time we run a survey quick and we extracted lessons learned that have already influenced our planning of next events.
S Page produced a Data & Developer Hub prototype against plan and against my will but he was right ;) and broke the vicious circle.

[slide 25]
Misses
Problems resourcing Phabricator maintenance. Solution: move ownership to Greg.
Greg: do you see a theme? I get all the tools everyone uses. ;)
Bryan: and we're on time
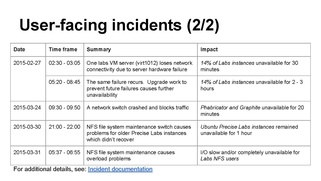
- Appendix slides
-

-

-
-

-
-

-
-
Feedback on meeting format[edit]
Lila: Feedback on meeting format?
Bryan: we started much earlier than normal to prepare slide deck (about a month ahead)
came together much better
could have had the slide deck template earlier
Greg: it's completely retrospective, no room to discuss planned work, needs from other teams
now disjoint goalsetting processes, q review meeting served for coordination before
Lila: dropped the "what's next" part of slides
if we do that separately, that's fine, but need to get together in some form
Lila: I like having all or most of the team in the meeting, even if only listening
could have everyone but managers remote
Greg: there's at least 60 in this group
my team asked me if they should be here
Quim: technical hangout limit (15)
Terry: technical limitations could be fixed
Bryan: there is value in team hearing questions that you ask, but this might not need to be in real time
don't ask geeky geeks to pay attention to something on screen for long ;)
Chad: I was supposed to sit in for the whole time, certainly enjoyed listening in, but it's not like I could jump in at any time[?]