Wikimedia monthly activities meetings/Quarterly reviews/Infrastructure, July 2015
Notes from the Quarterly Review meeting with the Wikimedia Foundation's Infrastructure and CTO departments, July 9, 2015, 9:00 am - 10:30 am PDT.
Please keep in mind that these minutes are mostly a rough paraphrase of what was said at the meeting, rather than a source of authoritative information. Consider referring to the presentation slides, blog posts, press releases and other official material

Present (in the office): Terry Gilbey, Dan Duvall, Chris Steipp, Grace Gellerman, Dario Taraborelli, Katherine Maher, Lila Tretikov, Kevin Leduc, Madhu Viswanathan, Geoff Brigham, Gabriel Wicke, Tilman Bayer (taking minutes), Abbey Ripstra, Daisy Chen, Leila Zia, Garfield Byrd, Stephen LaPorte, Kim Gilbey, James Forrester; participating remotely: Marcel Ruiz Forns, Yuvaraj Pandian, Aaron Halfaker, Arthur Richards, Mark Bergsma, Jonathan Morgan, Faidon Liambotis, Dan Andreescu, Chase Pettet, Chad Horohoe, Joseph Allemandou, Ori Livneh
Terry: welcome
Analytics
[edit]
[slide 4]
Kevin: had one goal:VE
dashboard's pageviews = measure of usefulness
Terry: do we know how much it cost to build?
Kevin: started in Q3, could look up #points... but maybe 1 person for 2 months

[slide 6]
core workflows and metrics
EventLogging: measure of success should be capacity, increased that
now can handle well over 1000 msg/second
Terry: incident defined as?
Kevin: data lost
Ori: clarify 6x perf increase means ...?
DanA: consumer itself got faster by that factor. See appendix for a link to the test.
before that, data was dropped at slower rates.

[slide 7]

[slide 8]
Kevin: reduced failed Wikimetrics reports
Terry: what's the value of that?
Kevin: shown in mailing list feedback: number of ppl who report problems about failed report and need support
Release Engineering
[edit]
[slide 10]
Dan D: I'm filling in for Greg, who can't be here today
released MW 1.25
deployment tooling: avoid wheel-reinventing
hard to give metrics since it was all research, but have a plan now
staging cluster: closer to production, but not affected by side effects

[slide 11]
Successes
team formed mid last year, lot of siloing
so worked to share knowledge more between us, via pairing sessions
also helped morale a lot

[slide 12]
about 1 person on each project, perhaps 2 for staging cluster, but needs broader participation
Terry: staging means?
DanD: relates to CI too, more deterministic deployment pipeling
Terry: so decision driven by resources, or complexity?
DanD: resources, remaining work seems straightforward
Terry: still think decision was right? yes
Chad: and work from this q was not in vain, e.g. already reduced some tech debt in puppet etc.
so it's not dropped forever
Terry: so just paused? yes
Services
[edit]
[slide 15]
Gabriel: top goal was support for mobile VE
section editing (just retrieve section instead of entire page)
built that API, but VE team disovered they need additional metadata e.g. for refs (which rely on entire page)
remove metadata: VE was not ready to consume
streamlined services deployment using Docker and Ansible; reduced code deploy steps from 11 to 3 by automating rolling deploys
working with Rel Eng on more general solutions, this might be something they could use

[slide 16]
created a new /api/rest_v1/ entry point in the main project domains, which brings big perf improvement for new requests by avoiding DNS lookups, separate HTTPS handshake

[slide 17]
Terry: resource issues for mobile VE
VE team has 3 engineers now, busy with rollout, bug fixes, not a lot of time for new things (even though they may have anticipated)
Dario: I still don't understand why we devote a lot of resources to mobile VE
Gabriel: API is independent of VE, can be useful [in other ways]
Lila: starting to break up article structure in general
assume VE best for new editors, and new eds are on mobile
Terry: shifted resources between parts of org, might need better coordination (on goals setting)
James: ...
Terry: sounds we spin up stuff in one part of org without [perfect synchronization in other parts]
James: IIRC this was stretch goal in VE with hard dependency on Services. Services did great
Technical Operations
[edit]
[slide 19]
Mark:
e.g. people outside Ops can/could not easily pool servers
and even for Ops people, workflow is smoother now

[slide 20]
Successes
had discussion with Services

[slide 21]
goals process used to be done a bit last minute, with only one goal, which didn't suit us well. now better

[slide 22]
Labs
[edit]
[slide 23]
had actually thought uptime goal was not very ambitious
for most of quarter, we hit it
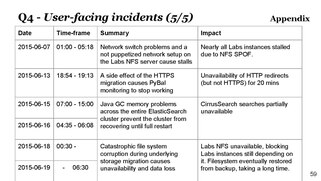
but then had a major almost 2 day outage some weeks ago

[slide 24]
implemented metrics
a lot of improvements, but not enough, because of remaining problems with underlying layers in Labs

[slide 25]
Misses
trying to make it more redundant actually impacted perf negatively (some decisions should have been made differently)
backup of large filesystem takes weeks on NFS, I (Mark) insisted on doing 2 backups (which saved us in case of the large outage), but means that latest backup is always old
Terry: had a SPOF here, had a SPOF earlier because of systems being in same cabinet
do we have SPOF analysis across systems?
Mark: per cluster yes, not for all systems
design was to have hot spare in place, but that too added to complexity
some bad design decisions were made, not a lot of ppl involved
Lila: alternative storage mechanisms?
Mark: yes, when I started working for WP 10 years ago I removed it [NFS] everywhere I could
Lila: might want to look at specialized hardware
Mark: assumption here [Labs] was that it's a (simple use case)
also thinking about offering different storage solutions to users
Lila: need to think ahead, e.g. in case we'll ...
do we have standby for NFS?
Mark: this was actually already redundant..., high availability setup
Lila: is it hot-hot?
Mark: it is hot-cold
Lila: I know, that setup can create more problems itself
Performance
[edit]
[slide 28]
Ori: had one goal only because team still being put together
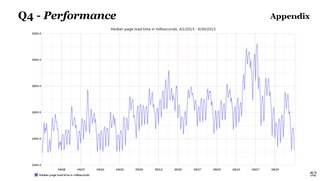
focused on page save time this q

[slide 29]
104% improvement
1.5 years of waiting time saved every month
--> Lila: please send me that slide together with what you just said [about waiting time saved/month]
(Ori:)
wish I had some project management support(?)
Research and Data
[edit]Dario:

[slide 31]
successful communication about that VE test

[slide 32]
still analyzing implication of French WP test (on article translation recommendations), but report is complete
revscoring also feeding into Q1 goal
Lila: what is the tangible effect on editor or reader of this?
Dario: internal customers are Search - surface quality of articles
for Editing team - surface quality of edit, e.g. revertable ones [in e.g. recent changes page]
Lila: next time explain this in a tangible way so it's understandable (eg. in case of article creation recommendations I understood it lead to an explosion of new article creations)
Aaron: have two on-wiki tools based on rev scoring that help ppl combat vandalism, and bots using it
Lila: quantify e.g. how much time it takes to process edits
this is amazing work, but I need to [be able to demonstrate it quantitatively]
--> Lila: quantify value we get from revscoring
Dario: could produce separate interim report about this
DanD: why does it need to have numbers? I understood it fine
Abbey: how about quality of experience for editors, that's important too
Lila: absolutely, it can also be stories to illustrate quality
Dario: team does a lot of end user affecting work, needs communications support

[slide 33]
VE was probably most important research project of year, and a complex one

[slide 34]
sucesses #2
one of the largest ever WP research workshops at ICWSM
Lila: Stanford project is about what?
Leila: 3 students extracted facts from Wikipedia, the goal is to digest to Wikidata
will talk about this in July research showcase
Lila: evaluate quality?
Leila: yes, pretty good
--> Lila: Dario: define pipeline research -> productization

[slide 35]
reorg was particularly taxing for Research team
still not completely settled
--> Lila: for all teams: assess how much of your time goes to:
- supporting others
- new projects
- prototyping / research
want to see a pie chart at end of q

[slide 36]
Appendix
Lila: great work
Terry: work
Dario: yes, also comms legal next
Terry: so that's a menu of services you provide?
Dario: pretty much, also self-service for some
Design Research
[edit]
[slide 38]
Abbey: obj 2
refocused because of lack of funding for software

[slide 39]
focus where we have survey data and academic papers to work from
migrated from Trello into Phabricator
Lila: list of Flow workflows we are investigating?
Abbey: not list, but examples. Jonathan?
Jonathan: just wrapped up interviews this week
about 12 different workflows, e.g. AfD, dispute resolution, deletion on Commons
more at Wikimania
Lila: that's great, I've been asking for this for a year
--> map superset of all editor workflows (everything we know of, does not need to be quantified / tested), and the subset that we focus on [with more research data]
Lila: there are so many things the current system does (because it can do anything), chip away, can't improve / substitute everything at once
to Aaron's comment on pipeline: a lot of research will lead not to productization, that's ok but need to map it still

[slide 40]
Abbey: Misses

[slide 41]
Security
[edit]Chris:
new team: me and Darian who joined in May
released risk assessment - if you want to scare yourself, read it ;)

[slide 43]
successes

[slide 44]
metrics: basic problem: "when we do our job, nobody knows"

[slide 45]

[slide 46]
core workflows and metrics
Terry: how bad is backlog?
Geoff: you work closely with Michelle on Legal, understand it's a good collaboration
Chris: yes. several people worked with me on privacy, takes up lot of my personal time. I think org needs a more centralized privacy role
Terry: new hire should help with sec reviews?
Chris: yes, but should also have automated reviews, which were cut out of the budget
Terry: thanks everyone,
these teams are on the backend
small groups of people with potentially very large impact
Lila: and thanks for stepping up, many of you have stepped up into leadership roles
- Further appendix slides
-

-

-

-
-

-
-
-
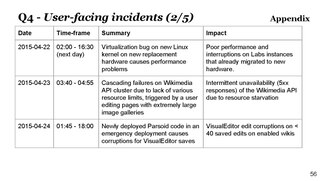
-
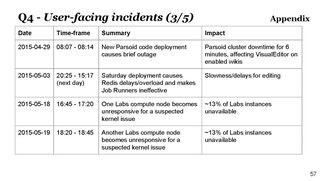
-

-