Wikimedia monthly activities meetings/Quarterly reviews/Infrastructure and CTO, October 2015
Notes from the Quarterly Review meeting with the Wikimedia Foundation's Infrastructure and CTO departments, October 8, 2015, 8:30am - 10:00am PDT.
Please keep in mind that these minutes are mostly a rough paraphrase of what was said at the meeting, rather than a source of authoritative information. Consider referring to the presentation slides, blog posts, press releases and other official material

Present (in the office): Abbey Ripstra, Leila Zia, Kevin Leduc, Terry Gilbey, Gabriel Wicke, Chris Steipp, Wes Moran, Greg Grossmeier, Tilman Bayer (taking minutes), Grace Gellerman, Daisy Chen, Guillaume Paumier, Ori Livneh, Chad Horohoe, Boryana Dineva, Geoff Brigham (from 9am), Lila Tretikov (from 9:17); participating remotely (via BlueJeans): Marcel Ruiz Forns, Mark Bergsma, Giuseppe Lavagetto, Joseph Allemandou, Dan Andreescu, Marko Obrovac, Nuria Ruiz, Eric Evans, Luis Villa, Antoine Musso, Faidon Liambotis and others (up to 28 remote attendees overall)
Intro
[edit]
[slide 2]
(Agenda)
Terry: Welcome

[slide 3]
Marcel:
Several huge tasks worked on in first two months, but only concluded in September - hence higher velocity for September

[slide 4]
Pageview API will be deployed this week

[slide 5]
EventLogging audit
reasons for miss: one DBA left, etc.

[slide 6]

[slide 7]
Eventlogging uses Kafka
Terry: does this mean it's now infinitely scalable by just throwing more hardware on it?
Marcel: no, there is probably still some limit
Terry: do we know what that limit might be
(Marcel:) no we have not tested that, but our tests confirm it is more than 10k ev/sec

[slide 8]
miss: we could not test load in our testing environment
Terry: do you have what you need to do a load test (for Kafka) next time?
Marcel: yes, decided to get test environment that allows some minimal load testing
Terry: budget needed?
Kevin: no
[slide 9]
(Marcel:)
core workflows
Terry: is there one thing ask from org to make you more successful?
Marcel: would need to think about that question
Terry: OK
Kevin: we get a lot of ad hoc requests for data
this is already in progress, but: transferring these to Reading (for traffic data) and Editing (for editing metrics) would help a lot

[slide 10]
Greg:
the three categories (strengthen/focus/experiment) didn't quite make sense for our team, so I added "Maintenance/interrupt"
KPI good enough for us now
errors went up, which is not good, but it means that others created buggy code, that we have to deal with

[slide 11]
Continuous Integration wait time: time CI jobs spend in queue before running
Terry: so the red line going down is good; what about the others?
Greg: red is just busy (resources)

[slide 12]
Restbase not migrated by eoq - but all the other things got done

[slide 13]
did not get Gerrit migrated, but prepared the basic stuff
Ops and us working on rest

[slide 14]
Skill matrix: distribute knowledge better within team
Wes: this idea is really cool
Ori: this is self-assessment?
Greg: yes
I guess we could do group assessment
Terry: this is a great map. even if self-assessment is not perfect, it's a great starting point
Greg: also "what we do (that we can help you with)" table on mediawiki.org
Terry: so this is the start of a menu of services
will also help avoid SPOF

[slide 15]
core workflows

[slide 16]
core workflows
--> Terry: figure out action items for Phabricator improvements, and see to fund them

[slide 17]
Gabriel:
KPI for us is API usage
moderate increase, no major endpoints that have switched over yet
Terry: req = 1 transaction through the API?
Gabriel: means HTTP request
a lot of usage is also on services level, e.g. by Google

[slide 18]
mobile team used to do a lot of content massaging (themselves)
now moved into service
both for iOS and Android
also, it's a lot quicker
proper caching prepared, not enabled yet
discovered that mobile web has actually very similar needs,
for work on supporting slow (2G) connections

[slide 19]
scale restbase, across data centers

[slide 20]
change / event propagation
e.g. Wikidata has to work around this, can't check (directly) where a Wikidata item is actually used
Wes: have you synced with Discovery team on this?
Gabriel: we will, not firmed up yet
I don't expect this to happen before 2nd half of coming quarter

[slide 21]
core workflows

[slide 22]
HTML save: not used yet, but will hopefully enable a lot of innovations like microcontributions
test coverage and deploy process helped avoid deployment outages (which would be really bad, e.g. edit corruption for VE)
good reuse of node.js service
Wes: how do you know [Cassandra sizes] got too large?
(Gabriel:) monitoring now
Wes: time?
Gabriel: elevated latency over several days
Wes: how do we communicate that (kind of issue)?
Gabriel: worked with Ops - it did not actually stop working, but higher error rate
went to discussion pages for VE etc. told people there was an issue and being fixed

[slide 23]
Mark: KPI: basically same as last q
want to point out that all of Engineering has part in that - please help us to keep it up ;)

[slide 24]
successful failover of eqiad cache traffic, no one noticed ;) had to do some procurement for that
so goal technically missed, but 99% there
leasing is a new process, collaboration with Finance, took longer
that made things a bit hectic in the end (but wasn't the eventual cause of missing this goal)
learn: allow time for dependent work
Terry: so did we get over the learning hump for leasing?
Mark: should have that sorted out now, it was due to initial contract review only.

[slide 25]
Mail tech debt
TLS encryption for email requested by Legal team
redefined OTRS goal after reviewing users' workflows etc with CA team
did meet redefined goal

[slide 26]
Security
there are some servers where we don't actually want/need firewalls, e.g. because of perf or because they are protected by other means
Terry: do we hav pen test scheduled?
Chris: no
we had an internal one last q
Mark: and had an external one at end of last year
--> Lila: would be good to have a policy to do pen tests once or twice a year

[slide 27]
Mark: (Labs reliability)
last quarter, tried to improve uptime of Labs and failed disastrously
better this quarter
NFS was unnecessary for many projects

[slide 28]
ToolLabs is on cluster environment (Gridengine) that was not quite made for this use case
evaluated two different environments and moved two tools over for testing
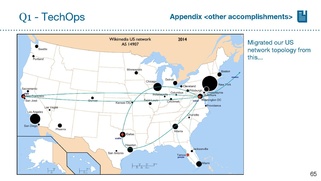
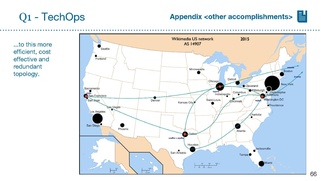
Mark: see appendix, also for Victor's new server photos
--> Lila: with the [complex] engineering projects that are coming along, I see need to think more about planning further ahead
sync earlier [between Ops and other teams] on complex scenarios

[slide 29]
Abbey: need to work on KPI, suggestions are welcome
--> Lila: I will try to help (to come up with KPI)

[slide 30]
Abbey: collaborate with other teams
4 examples: ...
hard to provide numbers as we often depend on other teams

[slide 31]
Mentoring

[slide 32]
pragmatic personas build on existing data, e.g. from surveys, academic research
Lila: how many personas do we get out of this?
Abbey: e.g. new editors,... [as example of personas]
Terry: did we only invite 12 editors?
Abbey: no, many more
Terry: show up rate?
would need to look up, but low
Wes: could CL help with that?
Abbey: yes, working with them

[slide 33]
participant database

[slide 34]
participant recruiter helps us with processes like mass emailing etc., brings a lot of experience with that
Voice and Tone: lots of Phabricator tickets on how UI communicates with users
e.g. "edit" vs. "edit source" - means different things to community members and others
Lila: this is really important
this language is anchoring (expectations), just like (graphical) design elements do
Abbey: misses: switching costs are high for us when product teams reprioritize
Wes: was the annual roadmap (from offsite) a good tool?
Abbey: it was really useful for seeing what other teams are going to be doing
but not pertinent to this issue here
Terry: so message you earlier?
Abbey: yes, e.g. don't want to start recruiting, build prototype etc and then have to shelve it because of plan changes

[slide 35]
core workflows
planning work with U Washington students

[slide 36]
Leila: I'm filling in for Dario
no KPI, open to suggestions, but team does very diverse work

[slide 37]
revscoring
Lila: is ownership moving to editing team?
Leila: need to check with Aaron, but it's productionized
--> Lila: I worry about impact of revscoring, need sit down and see how it's going to be used
Dario and Aaron probably should talk to Trevor etc.
KPIs should be same as [or related to] top level KPIs
e.g. productivity of editors
so maybe multiple KPIs
Wes: Discovery also wants to use it, started to talk to Aaron
Lila: maximum impact for editors; should be able to say e.g. "caught 95% of spam on enwiki thanks to this tool"

[slide 38]
(Leila:)
Article recommendation tests
CX needed bug fixes for PL WP, PL community asked to hold off on test for that reason

[slide 39]
measuring value added
decided to defer this, because revscoring needed a lot of help

[slide 40]
article recommendation improvements (stretch goal)

[slide 41]
Misses: data analysis requests
--> Lila: for everyone in this room: clarify who owns what
e.g. Analytics team's job is not to provide data for everybody
Wes: Dario did good work on that project
Lila: great job on editor impact
would great to also work on reader engagement
Leila: planned for Q2

[slide 43]
Performance
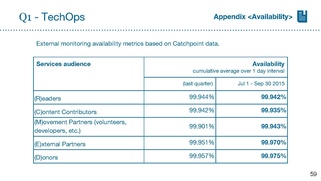
[edit]Ori: KPI
Lila: great
Terry: Ori has the only KPI that I like a minus in front of ;)

[slide 44]
Ori: page save time
attained goal in mid August, but hit by regression then
Lila: do we have test runs in CI?
that stuff should be caught on nightly basis

[slide 45]
Ori: first paint time < 900ms
this was a stretch goal
saw presentation by Paul Irish on importance of being under 1 sec
so aimed for that
Lila: this is awesome
--> Lila: blink of an eye is 200ms, we should aim for that [for first paint time]

[slide 46]
Ori: first paint time vs. signups per second; interesting, should look closer

[slide 47]
proud of hires
multi dc project, RfC - I think Ops enjoys working with us on that
Mark: absolutely, thanks for picking this up
Security
[edit]
[slide 48]
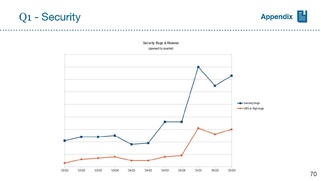
Chris: security bugs are not public, so looking for better KPI

[slide 49]
Automated Dynamic Scanning

[slide 50]
Metrics for Security Bugs

[slide 51]
other successes and misses:
not enough time scheduled for Analytics cluster assessment, but found several relevant things already

[slide 52]
core workflows
most of our work is core
working with Comms to better communicate post incident
--> Lila: consider #security incidents as KPIs
Lila: thanks everyone
- Appendix slides
-

-

-

-

-

-

-
-
-
-

-

-
-
-

-

-

-