
Research:Exploration on content propagation across Wikimedia projects/first round of analysis
Wikipedia is a collaborative initiative to build a universal and multilingual online encyclopedia. Currently, there are more than three hundred languages available as wikipedia projects. Our work intends to model the propagation of content across Wikipedia projects. We used a dataset of all pages created from 2001 to 2020 in every project existing. We divided the investigation into two phases. In the first, we focused on understanding how content propagation behaves in time, which features have more correlation to the propagation and analyze the probability of propagation. In the second phase, we evaluated the possibility to predict whether some content will or not propagate to other projects. Also, given that the content already propagated to a certain number of wikis, it is possible to predict with fair accuracy the next languages to which this content will propagate. Our model is capable of achieving high accuracy in both approaches. Our results would help Wikipedia managers to stop bad content (e.g., fake news) from spreading to other languages and also to potentialize the cascade of high-quality content.
Introduction
[edit]Wikipedia is an initiative born in 2001 and since then it is a reference for an online and cooperative encyclopedia. The success of Wikipedia is strongly related to the quality of its content since users should be able to trust the information available on the platform. On the other side, malicious people can use the platform’s reputation to spread false pieces of information with consequences in the real world, for instance, affecting elections or people’s careers. In both situations, the understanding of the process of knowledge propagation in the platform is a requirement. Once the mechanics are known, it is possible to boost good content cascading by selecting seeds of content to maximize the influence and increase the chance of cascading and also to stop bad content by the constant surveillance over the seed elements.
The Wikimedia community encompasses encyclopedia projects in several languages. Currently, there are around 309 different languages (e.g., English, Portuguese, and Catalan) hosted on the platform. Every page (e.g., a page about the country Brazil written in Portuguese) can have other instances about the same concept in other languages and the same identifier is shared between each version and the original article. Our dataset contains 13 million concepts and, from now on we call a concept a wiki item. If we consider all languages available for every wiki item we count more than 33 million pages. One way of studying the propagation of content is to focus on the mechanisms that cause some items to spread to several different languages and others not. We used the dataset presented to understand this cross-pollination of content over Wikipedia projects. In order to build an understanding of the data, we had to overcome some issues inherent to it. One issue is that the data lacks structural information. For every wiki item, we have a chronological list of different versions of this item in different languages with the time of the creation of each version and, because of this information, we model our data as a sequence of events where the event is the creation of another version of the same item. However, the structure of the propagation is implicit, in fact, the intuition is that the propagation follows a tree-like structure, where the parent items already exist when a new instance is created.
Another problem that we had to address is that long cascades are very rare and the majority of items have only one or few instances available. Our hypothesis is that for some cascades, we can model the propagation of content as a standard independent cascade epidemic model, which initially was developed to describe the behavior of disease propagation, but currently it is extensively used to model several other scenarios, such as social networks interaction and user behavior in e-commerce. Moreover, we assume influence exists to some degree, but in no way we are saying that all the content that exists in more than one language was created only and exclusively due influence from the parents' wiki items to the children.
This investigation of the content propagation is divided into two phases. In the first phase, we studied the patterns and dynamics of information spreading in the Wikipedia Projects dataset. In the second phase, our work addressed to the dataset problems to build a model that uses a well-known type of Recurrent Neural Network (RNN) called Long Short-term Memory Network (LSTM) to predict not just the probability of a certain sequence of pages of an item to continue the propagation, but also to predict the next languages to which this content will propagate. Our objective with the LSTM is to capture both immediate and long term relationships between languages. With this approach, we managed to understand the implicit structure of the cascading.
This manuscript is organized as follows: In Section 2, we present the terminology, the dataset, and overall statistical analysis. In Section 3, we introduce the problem of predicting certain content that will propagate, propose a model to the task, and present the results of our modeling. Section 4 presents the next language prediction problem, the modeling, and the results of our model. Section 5 concludes and lists possible future works.
Wikimedia Projects dataset
[edit]The dataset is a result of the collection of data from 2001 to the first trimester of 2020. In the following, we will present some terminology that will be used on the text. After, we characterize the data according to some chosen parameters.
Terminology
[edit]The text will refer to some terms particular to our dataset that need to be properly defined. The terms are:
- Item: a language-agnostic Wikidata id, used to describe a concept. For instance: Q298 (Chile);
- Page: a specific language instance of an item. For example, the Portuguese version of Q298 would be ptwiki-Q298 (aka. [[https://pt.wikipedia.org/wiki/Chil);
- Topic: a set of items belonging to the same topic (e.g. History). Note that the topic is assigned to the item label, and propagated to pages. Therefore, if item Q298 belongs to topic Geography, the page about Q298 in language X (Xwiki-Q298) would also belong to topic Geography. For more details on the taxonomy and topic model used, please refer to: [[https://wiki-topic.toolforge.org;
- Translation: Wikipedia offers an automatic translation tool ([[https://www.mediawiki.org/wiki/Content_translatio) that helps editors to article translations. Differently from pages created without the tool - where the content in two languages could be created completely independent from each other - the pages created by translations means an explicit flow of content from one language to another.
Data analysis
[edit]As Figure 1 shows, the data is composed of several entries and each entry contains three features. The first column refers to the Wikimedia Project, which also specifies a language. The Wikimedia convention is to use the language code followed by the expression “wiki”. Therefore, the project for the English language is “enwiki” and the same goes for all the other languages. The second column refers to items and, in Figure 1 we see that the same item is repeated, which means that this item is available in multiple different languages. The last column refers to the instant of the creation of a page. The instant of creation is represented by a 32-bit integer Unix timestamp.
| wiki_db | item_id | timestamp | |
|---|---|---|---|
| 0 | plwiki | Q1 | 1023468530 |
| 1 | svwiki | Q1 | 1038689254 |
| 2 | jawiki | Q1 | 1047585716 |
| 3 | fiwiki | Q1 | 1053504055 |
| 4 | frwiki | Q1 | 1059919453 |
| 5 | cswiki | Q1 | 1060075894 |
| 33173775 | dewiki | Q999999 | 1363358074 |
| 33173776 | enwiki | Q999999 | 1392016089 |
| 33173777 | ruwiki | Q999999 | 1393700731 |
| 33173778 | frwiki | Q999999 | 1410697709 |
| 33173779 | ruwiki | Q9999999 | 1399097156 |
| 33173780 | ttwiki | Q9999999 | 1512906397 |
The original dataset was cleaned from items not related to Wikipedias such as Wiktionary, Wikiquote, Wikibooks, and others. Also, we removed versions created by the automatic translation tool once we are interested in capturing user interaction with the content. After this cleaning process, we had a total of 309 different wiki projects. We analyzed the dataset growth since 2001 to characterize the wiki development regarding the number of items. We noticed that the number of pages is still growing linearly while the number of new items started to decelerate over the years. Which means that most of the content added to Wikipedia comes from different versions of already existing items. This context motivated our approach for studying content propagation in different pages of an item, since, over the years, there will be increasingly more pages than items. In our dataset, different pages of an item also mean that each page is in a different language. Figure 2 shows the cumulative fraction of the dataset for each size of cascade. We notice that the proportion of samples presents a logarithmic growth with the size of cascades. Around 67.22% of the dataset is composed of items with a single language available. The ratio reaches 90.08% for four or less pages. Once we rely on the data available on different versions of an item to model the problem, with more than half our samples not cascading, we had to work with a reduced share of the dataset.
-
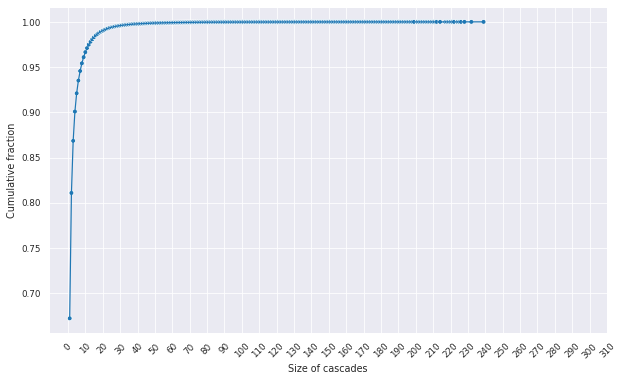 Figure 2 - Logarithmic growth of the cumulative fraction of cascades in the dataset based on the size of a cascade. Given a point in the chart (x, y). The y represents the proportion of the dataset composed from cascades smaller or equal to the x.
Figure 2 - Logarithmic growth of the cumulative fraction of cascades in the dataset based on the size of a cascade. Given a point in the chart (x, y). The y represents the proportion of the dataset composed from cascades smaller or equal to the x.

As an effort to understand the factors that influence cascades we correlate the length of these cascades with: (i) the year of creation of the item and (ii) the popularity rank of the first language of the item. It is intuitive that older items would have more pages than the new ones. However, the correlation of -0.32 indicates a low linear correlation between age of an item and number of pages. Even lower is the correlation between the first language and the number of pages. One can imagine that topics created in languages well known such as English, German or French would have more chances of propagating to other languages, but given the correlation of -0.06, this is not the case.
| Length of the cascade | |
|---|---|
| Rank of the first page languag | -0.06 |
| Year of item creation | -0.32 |
Another angle to look at the problem is to analyze the interval of creation between two consecutive pages. Figure 3 shows the distribution of intervals of creation between consecutive pages. Most new page creation occurs within an interval of one year from the last page. Therefore, the longer the inactivity of some item, the smaller is the likelihood of the item to become active again.
-
 Figure 3 - Density of the time interval between two consecutive pages of the same item. We noticed that if propagation does not occur after the first year, the probability decreases considerably.
Figure 3 - Density of the time interval between two consecutive pages of the same item. We noticed that if propagation does not occur after the first year, the probability decreases considerably.

Table 2 shows the behaviour of the creation of new pages according to the size of Wikipedia Projects. We wanted to verify if the popularity of the language of some page affects the next page language. We classified Wikipedia Projects as large projects and small projects. Formally, to classify the projects we ranked each language according to the number of items existing. Then from the largest to the smallest, we summed the number of items until we reached a certain ratio. Table 2 has 3 ratios: 10/90, 20/80, and 50/50. We noticed that, independently of the ratio, the creation of a new pages from small to small projects always represents the largest share.
| Number of Languages | 1/308 | 2/307 | 9/300 |
|---|---|---|---|
| Ratio of Items | 10/90 | 20/80 | 50/50 |
| Large→Large | 0% | 2.36% | 23.18% |
| Small → Small | 79.1% | 71.12% | 35.63% |
| Large → Small | 14.08% | 17.22% | 23.82% |
| Small → Large | 6.81% | 9.28% | 17.36% |
We know that there are more small projects that large and this can cause some distortion in the results. To evaluate this distortion, we computed the flow of page creation comparing not just with the next page but with the next five pages. This way we computed the long influence of some languages. Table 3 shows the results and we can see the same patterns from Table 2 repeating.
| Number of Languages | 1/308 | 2/307 | 9/300 |
|---|---|---|---|
| Ratio of Items | 10/90 | 20/80 | 50/50 |
| Large→Large | 0% | 1.41% | 18.85% |
| Small → Small | 84.86% | 76.99% | 41.06% |
| Large → Small | 11.91% | 15.68% | 25.01% |
| Small → Large | 3.56% | 5.90% | 15.06% |
The task to establish some cause-effect relation between the creation of new pages and the already created ones is hard to solve since the dataset lacks structure information. Figure 4 shows an example of this issue. Figure 4 (a) shows the raw data. It is a sequence of instances in different languages of the same item. The languages are ordered from the oldest to the younger.
In Figure 4 (b), we show the graph that it is possible to infer from the data, where the nodes are the languages and the edges represent the influence of one language over the creation of another. Note that is a linear graph because the only data we have to create this graph is the chronological relation between each language. This modeling contradicts the intuition, shown in Figure 4 (c), where we show a more complex graph, which is still constrained by chronological order, but also assumes that some items might not influence the creation of others.
-
 Figure 4 (a) - A piece of the used dataset.
Figure 4 (a) - A piece of the used dataset. -
 Figure 4 (b) - Linear modeling of the data available.
Figure 4 (b) - Linear modeling of the data available. -
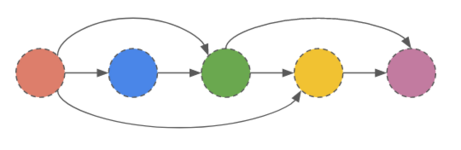 Figure 4 (c) - Intuition of the structure the data follows.
Figure 4 (c) - Intuition of the structure the data follows.



Our model should be able to get this long and short term relationship between sequential pages, also, needs to address all the issues and characteristics presented.
Prediction of Propagation
[edit]The correlation between the year of creation and the first language is not high, however, we see that the time interval between the creation of new pages is the inverse proportion to the likelihood of propagation. Another feature to analyze is the conditional probability with the set of existing pages of an item. Given that an item has K pages, which is the probability to propagate to a K+1. Figure 5 shows the probability for every K possible in the data. The tendency that the probability of propagation is related to the number of languages existing is evident. We notice that the probability increases very fast in the beginning. Then, we verify that the formation of big cascadings of languages is very rare because there is a threshold in the beginning of the cascading process that once it is overcome this barrier the cascading process is highly probable.
-
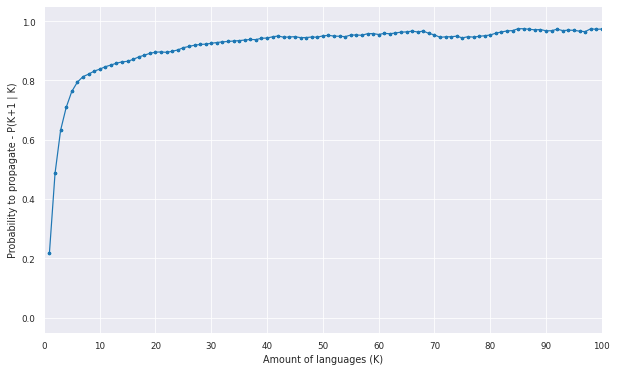 Figure 5 - Probability to propagate to a K+1 language given is already propagated to K.
Figure 5 - Probability to propagate to a K+1 language given is already propagated to K.

Based on the results from Figure 4, we know that long sets of predictions are highly probable to cascade, therefore, a simple model would just evaluate the size of the set of languages and predict propagation or not. However, the time between propagations is important. From the point of view of the Wikimedia platform, it is important to know if some content will propagate in a year, two years, or in a month. Then, we have established a timeout for propagation and it is used on our binary classifier model. Formally, our binary classifier outputs:


Given:
- P (K+1 | K) = Probability of a content to propagate to another language given K already existing.
- T(K+1) = creation timestamp of the page K+1.
- T(K) = creation timestamp of the page K.
Using this formalization, we also solve some of the problems of an unbalanced dataset. Our trained model that performs the prediction is the following:
| Layer (Type) | Output Shape |
|---|---|
| Input Layer | Batch Size, K |
| Embedding | Batch Size, K, Number of Existing Languages |
| LSTM | Batch Size, Hidden Layer Size |
| Dense | Batch Size, Hidden Layer Size |
| Dropout | Batch Size, Hidden Layer Size |
| Dense (Softmax) | Batch Size, 1 |
Before the training, we need to encode the wiki name to some format that the model can compute. We choose to represent wikis as integers representing the rank of size. In that way, the largest wiki is 1 and the smallest is 309. This model has an input layer, which receives an encoded window of created pages of size K, followed by an embedding layer, which will make a transformation of the sequence of languages to a vector space. The Embedding layer is responsible for the space transformation in the input. We transform the wiki name to a vector of length 309. This vector is related every wiki to the other using Jaccard Index or Jaccard similarity coefficient.
The Jaccard Index computes the similarity between two Wikimedia Projects using the set of items. Formally, it computes intersection over union shown below:

-
 Figure 6 (a) -Intersection of sets A and B.
Figure 6 (a) -Intersection of sets A and B. -
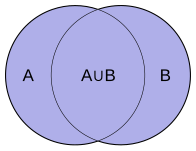 Figure 6 (b) - Union of sets A and B.
Figure 6 (b) - Union of sets A and B.


The representation of each language is in a 309-dimensional vector, therefore we needed to use some high-dimensional visualization tool. The tool chosen is the t-SNE (t-Distributed Stochastic Neighbor Embedding), which uses an stochastic algorithm to reduce the dimensionality of the data and allows the visualization. The Jaccard Index for the 15 largest wikis that represent more than 64% of the dataset. We noticed that most languages are grouped by lexical or cultural similarity, such as the group Swedish and Norwegian or Catalan, Spanish and Portuguese, Ukrainian and Russian, Italian and French. We also noticed that some languages are far from its groups such as Dutch and German. Our hypothesis is that, since we are not comparing lexical or cultural resemblance, but grouping together languages with similar behaviour in Wikipedia, these languages have different forms of propagation.
-
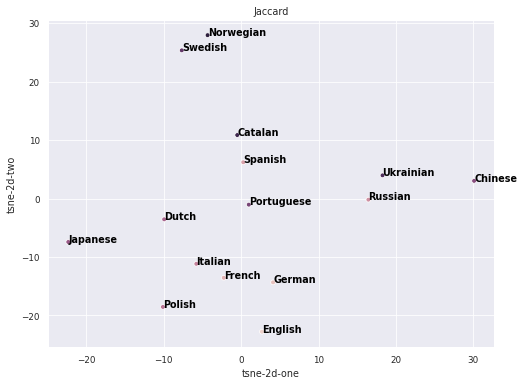 Figure 7 - T-SNE visualization of embedding with seed 53291. The shows a two-dimension representation of the Jaccard Index of one wiki project with relation to all the others. The original data is a matrix of 309x309 which is the number of languages (projects) and each row contains the Jaccard Index of one language against all the others. In this representation, we noticed that the Jaccard Index tends to represent in the same way languages that are lexically closer such as Catalan, Spanish and Portuguese.
Figure 7 - T-SNE visualization of embedding with seed 53291. The shows a two-dimension representation of the Jaccard Index of one wiki project with relation to all the others. The original data is a matrix of 309x309 which is the number of languages (projects) and each row contains the Jaccard Index of one language against all the others. In this representation, we noticed that the Jaccard Index tends to represent in the same way languages that are lexically closer such as Catalan, Spanish and Portuguese.

We can also compare the embedding results with cultural similarity. The following work used questions about values to compute a similarity index (available at: http://userpage.fu-berlin.de/~jroose/index_en/main_indexvalues.htm) our embedding has a similar pattern. For instance. Norway and Sweden have a cultural similarity index of 0,721, Portugal and Spain 0,801 and, Russia and Ukraine 0,801. On the other hand, Norway and Portugal are not so similar with an index of 0,611. After the embedding layer, we added an LSTM layer that will capture long and short-term relations in the input. The full connected dense layer selects the best features. The dropout layer avoids overfitting and the last layer converts the output in a single value being the probability of propagation of the input. We trained this model with 200000 samples, with a batch size of 10000 samples for 200 epochs. The evaluation used 100000 samples. The results are shown in Figure 8. The timeout was set as one year and K to 4. Given this timeout and K, the ratio of propagation in the test samples is around 79.10%.
-
 Figure 8 - Confusion matrix of the binary model evaluation for 100000 samples
Figure 8 - Confusion matrix of the binary model evaluation for 100000 samples

The metric used to evaluate our model was AUC (Area Under the Curve), which is common for binary problems. The AUC for the evaluation is 0.9743 (the closer to one the best) and the accuracy is 95.79%. The confusion matrix shows that the model is very good for predicting not propagations. The reason might be the fact that small sets of translates are very unlikely to propagate. If the model is capable of detecting that the input is a small dataset, the accuracy will increase. Overall, the performance is satisfactory and it proves that there is a signal that an LSTM RNN model is capable of interpreting. We evaluated for other timeouts and the results were similar to the measures for one year.
Next language prediction
[edit]Section 3 explored the task to predict the propagation of content. We had to set a few constraints such as the window of observation (K) and a timeout to make the problem more useful. However, the good results in the previous task opens the possibility of not just compute the probability of propagation, but to predict the next language or languages in the cascading. For this task, we continued in the approach of using LSTM to capture long and short-term interactions between the creation of new pages. We modified the model used in Section 3, since we need to make the model more expressive. In the last layer, we select the language with the biggest probability of coming next.
| Layer (Type) | Output Shape |
|---|---|
| Input Layer | Batch Size, K |
| LSTM | Batch Size, K, LSTM units |
| Dropout | Batch Size, LSTM units |
| LSTM | Batch Size, LSTM units |
| Dense | Batch Size, LSTM units |
| Softmax | Batch Size, Number of Existing Languages |
The model is a recurrent neural network composed of an input layer, which receives the input data and forward to the next layer. After, there are two LSTM layers with a dropout in the middle. This concatenation of LSTM improves the sensibility of the model. After the LSTM, we have to use a fully connected dense layer to convert the output to the desired output size. The output in this model is the next language and, because encoded the output as a one-hot encoding, the output dimension is the size of the existing number of languages. After the fully connected layer, we use a softmax to normalize the output of the previous layer into a probability distribution. We compiled the results in Figure 9. We show the accuracy of our model to predict one of the next languages to which a content will propagate. The input is the first four languages created in an item, therefore, we have excluded items with a set of languages smaller than five. To compute the accuracy, we check if the predicted language is in the selected window of next languages. The accuracy for a window of size 1 (i.g. immediate next language) is 24.31%. As the window increases, the accuracy for a window of size 5 is 43.96%. When we compare the results with the Table 1, we have enough evidence that indicates that we are not just guessing that the next language is one of the large projects, because the propagation from small projects to large projects is not much more probable than the other kinds. In the propagation task, popularity is not a relevant feature.
-
 Figure 9 - Next page prediction accuracy given a window size N. Given K existing languages, we predict a language and we look in the cascade in the K+N elements, where N is the x-axis. We consider the prediction to be right if the predicted language is within this window of size N.
Figure 9 - Next page prediction accuracy given a window size N. Given K existing languages, we predict a language and we look in the cascade in the K+N elements, where N is the x-axis. We consider the prediction to be right if the predicted language is within this window of size N.

The results show a strong signal in the data and indicating that the task of performing a prediction of the next language is feasible.
Conclusion and Future Works
[edit]The project had the objectives of investigating the propagation of content between languages. The investigation was divided into two tasks: (i) to predict if some item will start or continue to cascade, and; (ii) once an element will propagate to other languages, we should predict which one. Our results found 95.79% of accuracy for a binary classifier using LSTM as the core of the model. The second task of predicting the next language had a accuracy of 24.31% for predicting the immediate next language and when we look further in the cascading for the presence of the predicted language our accuracy increases, for instance, 43.96% is de accuracy when we check the presence of the predict next language in the next five pages of an item. We had to address several problems inherent to the data. The use of LSTM neural networks had the job to overcome these issues. We considered the motivation of LSTM to fit in our problem description. The results show that this approach is capable of good results, however there is still space for improvements. For future work, the graph inference of the propagation is a good start. The graph inference can use the tools developed to understand disease propagation to map the cross-pollination of content. Our work also needs to incorporate other information to the used data. Shared links between different versions of pages, the similarity of content of different pages and any other information that helps to infer the structure of the propagation.