
Research:Newsletter/2024/July

Vol: 14 • Issue: 07 • July 2024 [contribute] [archives]
STORM: AI agents role-play as "Wikipedia editors" and "experts" to create Wikipedia-like articles, a more sophisticated effort than previous auto-generation systems
By: Tilman Bayer
STORM: AI agents role-play as "Wikipedia editors" and "experts" to create Wikipedia-like articles
[edit]A paper[1] presented in June at the NAACL 2024 conference describes "how to apply large language models to write grounded and organized long-form articles from scratch, with comparable breadth and depth to Wikipedia pages." A "research prototype" version of the resulting "STORM" system is available online and has already attracted thousands of users. This is the most advanced system for automatically creating Wikipedia-like articles that has been published to date.
The authors hail from Monica S. Lam's group at Stanford, which has also published several other papers involving LLMs and Wikimedia projects since 2023 (see our previous coverage: WikiChat, "the first few-shot LLM-based chatbot that almost never hallucinates" – a paper that received the Wikimedia Foundation's "Research Award of the Year" some weeks ago).
A more sophisticated effort than previous auto-generation efforts
[edit]Research into automated generation of Wikipedia-like text long predates the current AI boom fueled by the 2022 release of ChatGPT. However, the authors point out that such efforts have "generally focused on evaluating the generation of shorter snippets (e.g., one paragraph), within a narrower scope (e.g., a specific domain or two), or when an explicit outline or reference documents are supplied." (See below for some other recent publications that took such a more limited approach. For coverage of an antediluvian historical example, see a 2015 review in this newsletter: "Bot detects theatre play scripts on the web and writes Wikipedia articles about them". The STORM paper cites an even earlier predecessor from 2009, a paper titled "Automatically generating Wikipedia articles: A structure-aware approach", which resulted in this edit.)
The STORM authors tackle the more general problem of writing of a Wikipedia-like article about an arbitrary topic "from scratch". Using a novel approach, they break this down it into various tasks and sub-tasks, which are carried out by different LLM agents:
"We decompose this problem into two tasks. The first is to conduct research to generate an outline, i.e., a list of multi-level sections, and collect a set of reference documents. The second uses the outline and the references to produce the full-length article. Such a task decomposition mirrors the human writing process which usually includes phases of pre-writing, drafting, and revising [...]"
The use of external references is motivated by the (by now well-established) observation that relying on the "parametric knowledge" contained in the LLM itself "is limited by a lack of details and hallucinations [...], particularly in addressing long-tail topics". ChatGPT and other state-of-the art AI chatbots struggle with requests to create a Wikipedia article. (As Wikipedians have found in various experiments – see also the Signpost's November 2022 coverage of attempts to write Wikipediesque articles using LLMs – this may result e.g. in articles that look good superficially but contain lots of factually wrong statements supported by hallucinated citations, i.e. references to web pages or other publications that do not exist.) The authors note that "current strategies [to address such shortcomings of LLMs in general] often involve retrieval-augmented generation (RAG), which circles back to the problem of researching the topic in the pre-writing stage, as much information cannot be surfaced through simple topic searches." They cite existing "human learning theories" about the importance of "asking effective questions". This task in turn is likewise challenging for LLMs ("we find that they typically produce basic 'What', 'When', and 'Where' questions [...] which often only address surface-level facts about the topic".) This motivates the authors' more elaborated design:
"To endow LLMs with the capacity to conduct better research, we propose the STORM paradigm for the Synthesis of Topic Outlines through Retrieval and Multi-perspective Question Asking.
The design of STORM is based on two hypotheses: (1) diverse perspectives lead to varied questions; (2) formulating in-depth questions requires iterative research."
"STORM models the pre-writing stage by (1) discovering diverse perspectives in researching the given topic, (2) simulating conversations where writers carrying different perspectives pose questions to a topic expert grounded on trusted Internet sources, (3) curating the collected information to create an outline."
Role-playing different article-writing perspectives
[edit]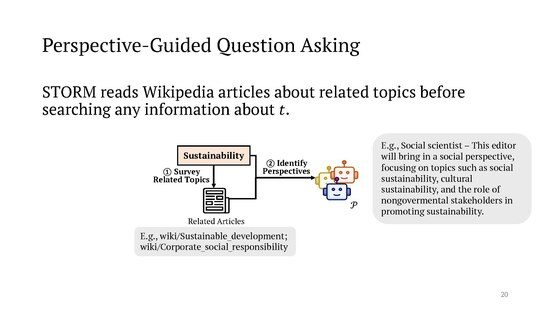
In more detail, after being given a topic to write about, STORM first "prompts an LLM to generate a list of related topics and subsequently extracts the tables of contents from their corresponding Wikipedia articles, if such articles can be obtained through Wikipedia API". In an example presented by the authors, for the given topic "sustainability of Large Language Models", this might lead to the existing articles sustainable development and corporate social responsibility. The section headings of those related articles are then passed to an LLM with the request to generate a set of "perspectives", with the prompt
You need to select a group of Wikipedia editors who will work together to create a comprehensive article on the topic . Each of them represents a different perspective , role , or affiliation related to this topic [...].
In the authors' example, one of the resulting perspectives is a "Social scientist – This editor will bring in a social perspective, focusing on topics such as social sustainability, cultural sustainability, and the role of nongovermental [sic] stakeholders in promoting sustainability."
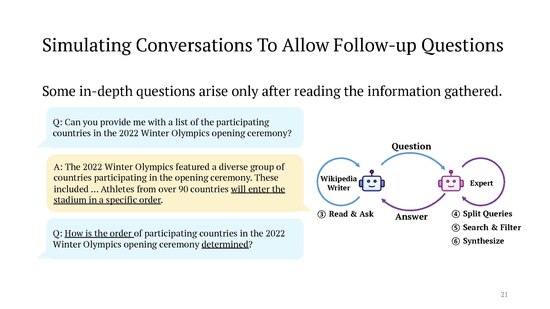
Each of these "Wikipedia editors" then sets out to interview a "topic expert" in their field of interest, i.e. the system simulates a conversation between two LLM agents prompted to act in these roles. The "expert" is instructed to answer the "Wikipedia editor"'s questions by coming up with suitable search engine queries and looking through the results. From the various prompts involved:
You are an experienced Wikipedia writer and want to edit a specific page. Besides your identity as a Wikipedia writer, you have a specific focus when researching the topic. Now, you are chatting with an expert to get information. Ask good questions to get more useful information [...] You want to answer the question using Google search. What do you type in the search box? [...] You are an expert who can use information effectively. You are chatting with a Wikipedia writer who wants to write a Wikipedia page on topic you know. You have gathered the related information and will now use the information to form a response. [...] Try to use as many different sources as possible and add do not hallucinate.
The online version of the STORM tool allows one to watch these behind-the-scenes agent conversations while the article is being generated, which can be quite amusing. (The "Wikipedia editor" is admonished in the prompt to politely express its gratitude to the "expert" and not to waste their time with repetitive questions: "When you have no more question to ask , say " Thank you so much for your help !" to end the conversation . Please only ask one question at a time and don 't ask what you have asked before .") The authors are currently working on a follow-up project called "Co-STORM" where the (human) user can become part of these multi-round agent conversation, e.g. to mitigate some remaining issues like content that is repetitive or conflicts between the different "experts".
(Like the aforementioned use of externally retrieved information, such agent-based systems have become quite popular in LLM-based AI over the last year or so. The authors use DSPy – a framework likewise developed at Stanford – for their implementation. Another well-known framework is LangChain, who actually released their own implementation of STORM as a demo of their "Langgraph" library back in February, based on the description and prompts in a preprint version of the paper, and shortly before the paper's authors published their own code.)
The paper states that the results of the "experts'" search engine queries "will be evaluated using a rule-based filter according to the Wikipedia guideline [Wikipedia:Reliable sources] to exclude untrustworthy sources" before the "experts" use them to generate their answers. (In the published source code, this is implemented in a somewhat simplistic way, by excluding those sources that Wikipedians have explicitly marked as "generally unreliable", "deprecated" or "blacklisted" at Wikipedia:Reliable sources/Perennial sources. But of course, search engine results contain many other sources on the internet that don't match the WP:RS requirements, either. In this reviewer's experiments with the STORM system, that turned out to be a significant limitation, at least if one were to use the output as basis for creating an actual Wikipedia article. One idea might be to restrict search to a search engine such as Google Scholar. But academic journal paywalls represent a challenge to this idea, according to a conversation with one of the authors.)
Putting the article together
[edit]Having gathered material from those agent conversations, STORM proceeds to generating an outline for the article. First, the system prompts the LLM to draft the outline only based on its internal (parametric) knowledge, which "typically provides a general but organized framework." This is then refined based on the results of the perspective-based conversations.
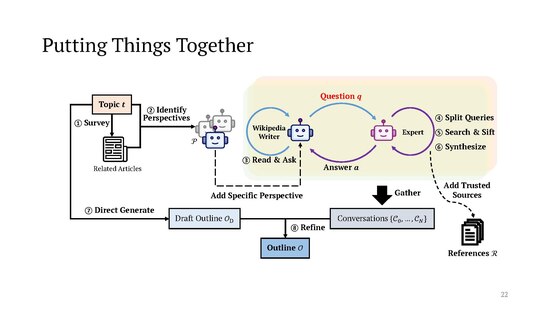
Lastly, the system composes the full article section by section, using the outline and the set of all reference documents R collected by the "topic experts". Another complication here is that "since it is usually impossible to fit the entire R within the context window of the LLM, we use the section title and headings of its all-level subsections to retrieve relevant documents from R based on semantic similarity". The LLM is then prompted separately for each section to generate its text using the references selected for that section. The sections are then concatenated into a single document, which is passed once more to the LLM with a prompt asking it to remove duplications between the sections. Finally, the LLM is called one last time to generate a summary for the lead section.
All this internal chattiness and repeated prompting of the LLM for multiple tasks comes at a price. It typically costs about 84 cent in market price API fees to generate one article (when using OpenAi's top-tier model GPT 4.0 as the LLM, and including the cost of search engine queries), according to an estimate shared by one of the authors last month. However, the freely available research prototype of STORM is supported by free Microsoft Azure credits. (This reviewer incurred roughly comparable costs when trying out the aforementioned LangChain implementation, also using GPT 4.0.) On the other hand, a reviewer at the website "R&D World" (see coverage in this issue's "In the Media") reported getting "A draft article in minutes for $0.005" while running the STORM code on Google Colab (albeit possibly by relying on initial free credits from OpenAI too).
Evaluating article quality
[edit]So are all these extra steps worth it, compared to simpler efforts (like asking ChatGPT "Write a Wikipedia article about...")?
First, to enable automated evaluation, the authors "curate FreshWiki, a dataset of recent high-quality Wikipedia articles, and formulate outline assessments to evaluate the pre-writing stage." The FreshWiki articles are used as ground truth, to "compute the entity recall in the article level" (very roughly, counting how many terms from the human-written reference article also occur in the auto-generated article about the topic) and the similar ROUGE-1 and ROUGE-L metrics (which measure the overlap with the reference text on the level of single words and word sequences).
The author compare their system to "three LLM-based baselines", e.g. "Direct Gen, a baseline that directly prompts the LLM to generate an outline, which is then used to generate the full-length article." They find that STORM indeed comes out ahead on these scores.
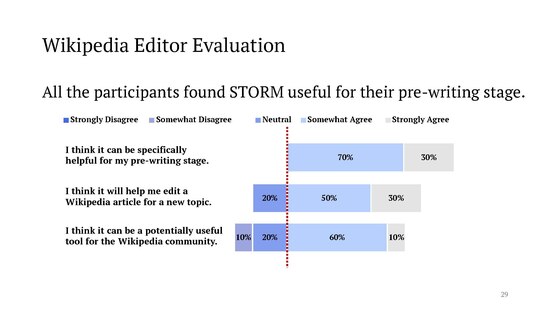
For manual evaluation, the authors invited [1] [2]
"a group of experienced Wikipedia editors for expert evaluation. The editors found STORM outperforms an outline-driven RAG baseline, especially regarding the breadth and organization of the articles. They also identified challenges for future research, including addressing cases where: (1) the bias on the Internet affects the generated articles; (2) LLMs fabricate connections between unrelated facts."
Checking citations
[edit]Another part of the automated evaluation checks whether the cited passages in the reference document actually support the sentence they are cited for. This problem is known as textual entailment in natural language processing. The authors entrust these checks to a current open-weight LLM (Mistral 7B-Instruct). This choice may be of independent interest to those seeking to use LLMs for automatically checking text-source integrity on Wikipedia.
They find that
"around 15% sentences in generated articles are unsupported by citations. We further investigate the failure cases by randomly sampling 10 articles and an author manually examines all the unsupported sentences in these articles. Besides sentences that are incorrectly split, lack citations, or are deemed supported by the author’s judgment [i.e. where Mistral 7B-Instruct incorrectly concluded that the citation had not supported the sentence], our analysis identifies three main error categories [...]: improper inferential linking, inaccurate paraphrasing, and citing irrelevant sources."
As a concrete example of such irrelevant sources, in this reviewer's test with creating an article on the German Press Council (Deutscher Presserat – a long-tail topic where not too many high-quality English-language online sources exist), the otherwise quite solid list of references included several pages about the wrong entity: One about the Luxembourgian press council, another about the unrelated German Ethics Council, and a third one about Germany and the UN Security Council. This seems primarily a failure in the search engine retrieval stage, rather than a LLM hallucination problem per se. But it was also not caught by the "topic experts" despite being prompted to "make sure every sentence is supported by the gathered information".
Conclusion and outlook
[edit]The authors take care to avoid the impression that STORM's outputs can already match actual Wikipedia articles in all respects (only asserting that the generated articles have "comparable breadth and depth to Wikipedia pages"). Their research project page on Meta-wiki is diligently titled "Wikipedia type Articles Generated by LLM (Not for Publication on Wikipedia)". Nevertheless, STORM represents a significant step forward, bringing AI a bit closer to replacing much of the work of Wikipedia article writers.
On July 11, one of the authors presented the project at a Wikipedia meetup in San Francisco, and answered various questions about it (Etherpad notes). Among others aspects already reported above, he shared that STORM had already attracted around 10,000 users (signups) who use it for a variety of different uses cases – not just as a mere Wikipedia replacement. The project has received feature requests from various interested parties, which are being implementing by a small development team (3 people), as visible in the project's open-source code repository.
Other recent publications
[edit]Other recent publications that could not be covered in time for this issue include the items listed below. Contributions, whether reviewing or summarizing newly published research, are always welcome.
.png)
"Retrieval-based Full-length Wikipedia Generation for Emergent Events" using ChatGPT and other LLMs
[edit]From the abstract:[2]
"[...] previous efforts in Wikipedia generation have often fallen short of meeting real-world requirements. Some approaches focus solely on generating segments of a complete Wikipedia document, while others overlook the importance of faithfulness in generation or fail to consider the influence of the pre-training corpus. In this paper, we simulate a real-world scenario where structured full-length Wikipedia documents are generated for emergent events [e.g. 2022 EFL League One play-off final] using input retrieved from web sources. To ensure that Large Language Models (LLMs) are not trained on corpora related to recently occurred events, we select events that have taken place recently and introduce a new benchmark Wiki-GenBen, which consists of 309 events paired with their corresponding retrieved web pages for generating evidence. Additionally, we design a comprehensive set of systematic evaluation metrics and baseline methods, to evaluate the capability of LLMs in generating factual full-length Wikipedia documents."
From the paper:
"Our experiments are conducted using two variants of ChatGPT: GPT-3.5-turbo and GPT-3.5- turbo-16k, as well as open-source LLMs, including instruction-tuned versions of LLama2"
"A notable challenge observed across all models is their struggle to maintain the reliability of the content produced. The best-performing models reach citation metrics just above 50% and an IB Score around 10%, highlighting the complexity involved in generating accurate and reliable content."
The authors are a group of ten researchers from Peking University and Huawei. Published just six days after (the first version of) the "STORM" paper by Stanford researchers covered above, neither of the two papers cites the other.
"Surfer100: Generating Surveys From Web Resources, Wikipedia-style"
[edit]From the abstract:[3]
"We show that recent advances in pretrained language modeling can be combined for a two-stage extractive and abstractive approach for Wikipedia lead paragraph generation. We extend this approach to generate longer Wikipedia-style summaries with sections and examine how such methods struggle in this application through detailed studies with 100 reference human-collected surveys. This is the first study on utilizing web resources for long Wikipedia-style summaries to the best of our knowledge."
"GPT-4 surpasses its predecessors" in writing Wikipedia-style articles about NLP concepts, but still "occasionally exhibited lapses"
[edit]From the abstract:[4]
"we examine the proficiency of LLMs in generating succinct [Wikipedia-style] survey articles specific to the niche field of NLP in computer science, focusing on a curated list of 99 topics [adopted from the "Surfer100" dataset, see above]. Automated benchmarks reveal that GPT-4 surpasses its predecessors like GPT-3.5, PaLM2, and LLaMa2 in comparison to the established ground truth. We compare both human and GPT-based evaluation scores and provide in-depth analysis. While our findings suggest that GPT-created surveys are more contemporary and accessible than human-authored ones, certain limitations were observed. Notably, GPT-4, despite often delivering outstanding content, occasionally exhibited lapses like missing details or factual errors."
.png)
.png)
"Automatically Generating Hindi Wikipedia Pages using Wikidata as a Knowledge Graph: A Domain-Specific Template Sentences Approach"
[edit]From the abstract:[5]
"This paper presents a method for generating Wikipedia articles in the Hindi language automatically, using Wikidata as a knowledge base. Our method extracts structured information from Wikidata, such as the names of entities, their properties, and their relationships, and then uses this information to generate natural language text that conforms to a set of templates designed for the domain of interest. We evaluate our method by generating articles about scientists, and we compare the resulting articles to machine-translated articles. Our results show that more than 70% of the generated articles using our method are better in terms of coherence, structure, and readability. Our approach has the potential to significantly reduce the time and effort required to create Wikipedia articles in Hindi and could be extended to other languages and domains as well."
A master's thesis by one of the authors[6] covers the process in more detail.
(Neither the paper nor the thesis mention the Wikimedia Foundation's Abstract Wikipedia project, which is pursuing a somewhat similar approach.)
"Grounded Content Automation: Generation and Verification of Wikipedia in Low-Resource languages."
[edit]From the abstract:[7]
"we seek to [...] automatically generat[e] Wikipedia articles in low-resource languages to improve the quality and quantity of articles available. Our work begins with XWikiGen, a cross-lingual multi-document summarization task that aims to generate Wikipedia articles using reference texts and article outlines. We propose the XWikiRef dataset to facilitate this, which spans eight languages and five distinct domains, laying the groundwork for our experimentation. We observe that existing Wikipedia text generation tools rely on Wikipedia outlines to provide a structure for the article. Hence, we also propose Multilingual Outlinegen, a task focused on generating Wikipedia article outlines with minimal input in low-resource languages. To support this task, we introduce another novel dataset, WikiOutlines, which encompasses ten languages [Hindi, Marathi, Bengali, Odia, Tamil, English, Malayalam, Punjabi, Kannada and Telugu]. An important question with text generation is the reliability of the generated information. For this, we propose the task of Cross-lingual Fact Verification (FactVer). In this task, we aim to verify the facts in the source articles against their references, addressing the growing concern over hallucinations in Language Models. We manually annotate the FactVer dataset for this task to benchmark our results against it."
See also our earlier coverage of a related paper: "XWikiGen: Cross-lingual Summarization for Encyclopedic Text Generation in Low Resource Languages"
"Abstract Wikipedia is a challenge that exceeds previous applications of [natural language generation] by at least two orders of magnitude"
[edit]From the abstract:[8]
"Abstract Wikipedia is an initiative to produce Wikipedia articles from abstract knowledge representations with multilingual natural language generation (NLG) algorithms. Its goal is to make encyclopaedic content available with equal coverage in the languages of the world. This paper discusses the issues related to the project in terms of an experimental implementation in Grammatical Framework (GF) [a programming language for writing grammars of natural languages]. It shows how multilingual NLG can be organized into different abstraction levels that enable the sharing of code across languages and the division of labour between programmers and authors with different skill requirements."
From the "Conclusion" section:
Abstract Wikipedia is a challenge that exceeds previous applications of GF, or any other NLG project, by at least two orders of magnitude: it involves almost ten times more languages and at least ten times more variation in content than any earlier project.
See also w:Wikipedia:Wikipedia Signpost/2023-01-01/Technology report for a discussion of some technical challenges surrounding NLG on Abstract Wikipedia, including past debates about adopting Grammatical Framework for it
"Using Wikidata lexemes and items to generate text from abstract representations", with possible use on Abstract Wikipedia/Wikifunctions
[edit]From the abstract:[9]
"Ninai/Udiron, a living function-based natural language generation system, uses knowledge in Wikidata lexemes and items to transform abstract representations of factual statements into human-readable text. [...] Various system design choices work toward using the information in Wikidata lexemes and items efficiently and effectively, making different components individually contributable and extensible, and making the overall resultant outputs from the system expectable and analyzable. These targets accompany the intentions for Ninai/Udiron to ultimately power the Abstract Wikipedia project as well as be hosted on the Wikifunctions project."
"Censorship of Online Encyclopedias: Implications for NLP Models"
[edit]From the abstract:[10]
"We describe how censorship has affected the development of Wikipedia corpuses, text data which are regularly used for pre-trained inputs into NLP algorithms. We show that word embeddings trained on Baidu Baike, an online Chinese encyclopedia, have very different associations between adjectives and a range of concepts about democracy, freedom, collective action, equality, and people and historical events in China than its regularly blocked but uncensored counterpart - Chinese language Wikipedia. We examine the implications of these discrepancies by studying their use in downstream AI applications. Our paper shows how government repression, censorship, and self-censorship may impact training data and the applications that draw from them."
Briefly
[edit]- See the page of the monthly Wikimedia Research Showcase for videos and slides of past presentations.
- A "NLP for Wikipedia" workshop will take place as part of the Empirical Methods in Natural Language Processing conference on November 16, 2024. The paper submission deadline is August 29.
References
[edit]- ↑ Shao, Yijia; Jiang, Yucheng; Kanell, Theodore A.; Xu, Peter; Khattab, Omar; Lam, Monica S. (2024-04-08), Assisting in Writing Wikipedia-like Articles From Scratch with Large Language Models, arXiv, doi:10.48550/arXiv.2402.14207 NAACL 2024 Main Conference. Code, Online demo
- ↑ Zhang, Jiebin; Yu, Eugene J.; Chen, Qinyu; Xiong, Chenhao; Zhu, Dawei; Qian, Han; Song, Mingbo; Li, Xiaoguang; Liu, Qun; Li, Sujian (2024-02-28). "Retrieval-based Full-length Wikipedia Generation for Emergent Events". arXiv.org. Data and (prompting) code: https://github.com/zhzihao/WikiGenBench
- ↑ Li, Irene; Fabbri, Alex; Kawamura, Rina; Liu, Yixin; Tang, Xiangru; Tae, Jaesung; Shen, Chang; Ma, Sally; Mizutani, Tomoe; Radev, Dragomir (June 2022). "Surfer100: Generating Surveys From Web Resources, Wikipedia-style". In Calzolari, Nicoletta; Béchet, Frédéric; Blache, Philippe; Choukri, Khalid; Cieri, Christopher; Declerck, Thierry; Goggi, Sara; Isahara, Hitoshi; Maegaard, Bente; Mariani, Joseph; Mazo, Hélène; Odijk, Jan; Piperidis, Stelios. Proceedings of the Thirteenth Language Resources and Evaluation Conference. LREC 2022. Marseille, France: European Language Resources Association. pp. 5388–5392.
- ↑ Gao, Fan; Jiang, Hang; Yang, Rui; Zeng, Qingcheng; Lu, Jinghui; Blum, Moritz; Liu, Dairui; She, Tianwei; Jiang, Yuang; Li, Irene (2024-02-21), Large Language Models on Wikipedia-Style Survey Generation: an Evaluation in NLP Concepts, arXiv, doi:10.48550/arXiv.2308.10410
- ↑ Agarwal, Aditya; Mamidi, Radhika (2023). "Automatically Generating Hindi Wikipedia Pages using Wikidata as a Knowledge Graph: A Domain-Specific Template Sentences Approach" (PDF). Proceedings of the 14th International Conference on Recent Advances in Natural Language Processing. International Conference Recent Advances in Natural Language Processing. INCOMA Ltd., Shoumen, BULGARIA. pp. 11–21. ISBN 978-954-452-092-2. doi:10.26615/978-954-452-092-2_002.
- ↑ Agarwal, Aditya (June 2024). "Automatic Generation of Hindi Wikipedia Pages". IIIT Hyderabad Publications. (Master's thesis)
- ↑ Subramanian, Shivansh (2024-06-07). Grounded Content Automation: Generation and Verification of Wikipedia in Low-Resouce languages. (Thesis). IIIT Hyderabad. [sic]
- ↑ Ranta, Aarne (2023). "Multilingual Text Generation for Abstract Wikipedia in Grammatical Framework: Prospects and Challenges". In Loukanova, Roussanka; Lumsdaine, Peter LeFanu; Muskens, Reinhard. Logic and Algorithms in Computational Linguistics 2021 (LACompLing2021). Studies in Computational Intelligence. Cham: Springer International Publishing. pp. 125–149. ISBN 9783031217807.
 , Preprint version: https://www.grammaticalframework.org/~aarne/preprint-AAM-textgen.pdf , Code: https://github.com/aarneranta/NLG-examples
, Preprint version: https://www.grammaticalframework.org/~aarne/preprint-AAM-textgen.pdf , Code: https://github.com/aarneranta/NLG-examples
- ↑ Morshed, Mahir (2024-01-01). "Using Wikidata lexemes and items to generate text from abstract representations". Semantic Web. Preprint (Preprint): 1–14. ISSN 1570-0844. doi:10.3233/SW-243564. code: https://gitlab.com/mahir256/ninai / https://gitlab.com/mahir256/udiron
- ↑ Yang, Eddie; Roberts, Margaret E. (2021-03-01). "Censorship of Online Encyclopedias: Implications for NLP Models". Proceedings of the 2021 ACM Conference on Fairness, Accountability, and Transparency. FAccT '21. New York, NY, USA: Association for Computing Machinery. pp. 537–548. ISBN 9781450383097. doi:10.1145/3442188.3445916.
Wikimedia Research Newsletter
Vol: 14 • Issue: 07 • July 2024
About • Subscribe: Email ![]()
![]()
![]() •
[archives] • [Signpost edition] • [contribute] • [research index]
•
[archives] • [Signpost edition] • [contribute] • [research index]