
Research:Page view/Generalised filters
This page is currently a draft. More information pertaining to this may be available on the talk page. Translation admins: Normally, drafts should not be marked for translation. |
This page describes the generalised filters to be run over the Wikimedia request logs in order to subset "requests" to "pageviews, broadly-speaking", and some sensitivity analysis conducted to test the usefulness of each filter. After being passed through these filters, the requests will then be categorised and tagged to provide more granular breakdowns by access method, using the other filters.
Filtering by MIME type[edit]
if
- the MIME type is in:
text/html; charset=iso-8859-1text/html; charset=ISO-8859-1text/htmltext/html; charset=utf-8text/html; charset=UTF-8
- and the URL does not include "
api.php"
or
- the MIME type is in:
application/json
- and the user agent matches "
%WikipediaApp%OR%Wikipedia/5.0.%" - and
- the URI query includes "
sections=0"
- the URI query includes "
- OR
- the URI query includes "
sections=all" - and the user agent matches
%iPhone%"
- the URI query includes "
- and the URI path includes "
api.php"
include.
When we say the request logs contain all requests, we mean it; this includes images, internal API calls and the loading of JavaScript modules, amongst other things. These need to be filtered out, since almost all of them are not intentional user requests - the consequence of a search, or a click. Image requests and JavaScript requests largely come as a consequence of visiting a page; it's your browser requesting the site elements and page components necessary to construct the page, not the actual text content of the page. API requests tend to be either consequential (some of our search systems launch API requests, for example) or intentional, but from automated systems or for non-reading purposes.
A useful way of excluding the above examples is to use filtering by MIME type. What we care about is requests for HTML pages, and so we can limit to HTML-related MIME types as a way of excluding other requests. This is precisely what the existing system does, but it carries a problem - namely, that App requests for pages go though the API. The easiest solution is to limit the requests to non-API HTML MIME types, and requests with API mime types that match the traces left by page requests through the Apps.
Accepted HTML-related MIME types are variants on text/html; text/html itself, and also text/html with various encoding options specified (text/html; charset=UTF-8, for example). Identifying those is easy, although some (failed) API requests also appear to have a text/html MIME type, and so must be excluded.
Apps requests all have "WikipediaApp" or "Wikipedia/5.0." in their provided user agent, and use a variety of MIME types. Requests for pages, however, only use one: application/json. This requires further filtering, though, because App pageviews may appear as multiple requests: one for the first section, which includes sections=0 in the URL, and a second request for subsequent sections, with sections=1-N. The first request is the only one that is guaranteed to appear (since some pages do not have multiple sections), and so filtering to remove duplicate requests should remove those that aren't sections=0. See App identification for more details.
The resulting decision tree is found in the pseudocode in the "MIME type filtering" infobox.
Filtering to applicable sites[edit]
if:
- the URI host's subdomain matches:
(commons|meta|incubator|species), and;
- An optional URI host's subdomain matches:
(m|mobile|wap|zero), and;
- the URI host's domain matches:
wikimedia\\.org$
or:
- The URI host matches:
(wik(tionary|isource|ibooks|ivoyage|iversity|iquote|inews|ipedia|idata))\\.org$, and;
- the URI host does not consist of:
www.[match]donate*.[match]arbcom*.[match]
or:
- The URI host matches:
(mediawiki|wikidata|wikimediafoundation)\\.org$
- the URI host does not consist of:
test*.[match]
include.
As well as internal requests, we have a lot of external requests that we don't care about because either they're simply part of the way the sites function (login.wikimedia.org requests, for example), or they're not requests for properties that are directly part of our mission. The WMF hosts wikis for Chapters and other groups necessary for the movement's survival and growth - mediawiki.org for general MediaWiki information, for example, or Wikitech for Wikimedia-specific infrastructure information. These are all important projects for important groups, but those projects are not part of the set of questions that this set of traffic definitions intend to answer.
Our primary focus has to be the content Wikimedia projects - Wikipedia, Wikisource, Wiktionary, etc. - because that's the primary focus of the movement. While understanding the source of traffic for a site that indirectly assists the movement is useful, it doesn't help us in answering the research questions mentioned above and so isn't useful to incorporate into any definition. This is not to say we cannot or will not provide analytics for chapters or other sites, simply that the analytics will be ad-hoc, strictly demarcated from the "pageviews" count, or both.
So: the definition of "applicable sites" is any production Wikimedia property, aimed at our mission: the "Wiki" projects, (pedia, source, species, etc), including Wikidata, Wikimedia Commons, and Meta.[1]
The regular expression in the infobox to the right is intended to capture the "applicable sites". In testing, a high degree of accuracy was achieved.[2]
-
 Figure 1: traffic with the desired sites filter applied, versus no applied filters
Figure 1: traffic with the desired sites filter applied, versus no applied filters -
 Figure 2: traffic with all filters applied, versus traffic with all filters (minus the desired sites filter) applied.
Figure 2: traffic with all filters applied, versus traffic with all filters (minus the desired sites filter) applied.


The second test - the sensitivity analysis - produced the results seen in Figure 1. Without the filtering to exclude non-applicable sites, request numbers would triple. If we apply all of the other generalised filters, however, and compare (all generalised filters, minus the applicable site filter) to (all generalised filters), we get the result scene in Figure 2. The variation between the two lines is entirely artificial:[3] without the deliberate distinguishing of the lines, only one of them would appear, because the result is so similar. Of 1.1 million requests present after the application of all other filters, this filter only eliminated 1,264. This indicates that:
- The filtering is useful for eliminating requests that would otherwise be wrongly included, but;
- The actual error rate introduced by removing it is minuscule.[4] In the event that implementing this system requires processing time savings, this filter has the best return from elimination.
Filtering to content directories[edit]
if:
- the URI path matches:
^(/sr(-(ec|el))?|/w(iki)?|/zh(-(cn|hans|hant|hk|mo|my|sg|tw))?)/;
or:
- the URI query matches:
\\?((cur|old)id|title|search)=;
and:
- the URI query does not match:
action=edit
- nor:
action=submit
include.
Even after filtering by site and MIME, there's still some extraneous traffic. A good example of this (although it's not the only one) is search activity; searches on MediaWiki sites meet all of the other filters and tests but don't actually provide content for readers, just an aid in navigating to that content.
Historically we've excluded these requests by looking for the presences of directory names in the URL, namely /wiki/, which corresponds to MediaWiki content pages. Unfortunately, /wiki/ is not a consistent naming convention for that directory, and there are some (highly unorthodox) ways of accessing content that do not go through the existing directory structure.
The first problem is found on projects with a single language, but multiple dialects, such as the Chinese (zh) or Serbian (sr) projects. These projects use multiple directories to separate out pages written in different dialects, and that multiple directory structure does not follow the /wiki/ convention. To identify these, we performed a large hand-coding test on requests for assets that did not follow this convention, and identified a large number of new directories, incorporating them into the regular expression.[5] We performed sensitivity analysis comparing /w/ and /wiki/ to a regular expression also including the dialect directory variants, which is shown in Figure 5. This illustrates that the inclusion of the additional country codes makes a noticeable difference in how many 'valid' pageviews are extracted from a dataset (albeit a small one).
The second problem is found, well, everywhere. There are a couple of idiosyncratic ways of accessing actual content that do not involve the /wiki/ or /w/ directories, namely the ?curid= and ?title parameters, which accept (respectively) the ID of a specific revision, and a page title. These do not have a directory name behind them and so would be excluded under both the old and new directory filters. We performed sensitivity analysis here too, generating a preliminary final regex to do so.[6] The results are shown in Figure 6, with jitter again applied, because the difference made isn't actually that great when visualised. In numeric terms, though, we're talking about several million extra pageviews a day, which is worth including, particularly since they're likely to be pageviews biased towards particular projects.
-
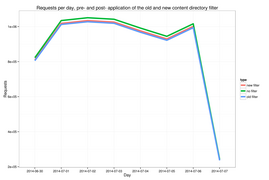 Figure 5: traffic with the new directory filter applied, compared to the old directory filter and no directory filter
Figure 5: traffic with the new directory filter applied, compared to the old directory filter and no directory filter -
 Figure 6: traffic with the updated new directory filter applied, compared to the datasets in Figure 5.
Figure 6: traffic with the updated new directory filter applied, compared to the datasets in Figure 5.


Additional filters include excluding "edit" attempts, which due to a change some time in late 2014/early 2015 now have a text/html MIME type.
Filtering to completed requests[edit]
if:
- the HTTP status code is
200, or: - the HTTP status code is
304
include.
Obviously, we don't want to include requests that weren't actually completed. We are trying to measure the actual communication of information to readers. This transfer of information can go wrong in a couple of ways - the server can screw up or the client can screw up, both indicated by HTTP status codes, which are stored in the http_status field in the request logs. Successful requests are indicated by a 200 status code, including "in-MediaWiki" redirects performed by #REDIRECT [[title]]. The only things that display differently are hard redirects - for example, entering a page name that is entirely lower case - which display as a 302 request, followed by a 200 request. Anything without a 200 code is either a failed request, or a subcomponent of a successful request that is also represented by a 200 within the dataset. The exception to this is 304 requests, which represent a client request for a page which, on checking, they confirm they have locally, and retrieve from their local store.
Accordingly, all requests that do not have the status codes 200 or 304 should be filtered out as part of the calculation of pageviews.
Filtering to exclude Special pages[edit]
if:
- The URI path includes
(BannerRandom|CentralAutoLogin|MobileEditor|Undefined|UserLogin|ZeroRatedMobileAcces);
or:
- The URI path includes
(CentralAutoLogin|MobileEditor|UserLogin|ZeroRatedMobileAccess);
Exclude
Next up are requests for special pages - parts of MediaWiki surfaced to users via an artificial namespace, "Special", that represent internal processes and reports rather than content. An example would be Special:RandomPage, which takes you to a random page, or Special:RecentChanges, a feed of recent alterations to the wiki. These pass all the previous filters but are nevertheless not content pages. Originally we debated simply considering them to not be pageviews, but decided that this was overkill: a lot of Special pages are, in fact, deliberately navigated to.
Instead we have opted to exclude specific special pages, which can be found in the pseudocode above.
Filtering by x_analytics header[edit]
if
- the x_analytics header contains tag:
pageview
and
- the x_analytics header does NOT contains tag:
preview
include.
In order to facilitate pageview correctness, we are (as of 2015/16) slowly pushing toward defining if a request is a pageview at request-time already. We ask teams to use the x_analytics header to tag their requests for us to easily retrieve which are pageviews or not. On 2015-09-17, the mobile apps team tags previews for us to remove them from the pageview count. On 2016-03-23 we started to receive pageview=1 in the x_analytics header to positively define pageviews.
Footnotes[edit]
- ↑ The argument has (reasonably) been raised that if we plan to gather data for pages in the non-article namespace, this is effectively the same as gathering data on pageviews on Meta.
- ↑ It was 100% using some sampled logs, but that's not on a tremendously large sample given the frequency of our requests; we'll need to do further testing down the line.
- ↑ Achieved with the application of
geom_line(position = "jitter") - ↑ 0.11173%
- ↑
/sr(-(ec|hl|el))?/and/zh(-(tw|cn|hant|mo|hans|hk|sg))?/ - ↑
(/zh(-(tw|cn|hant|mo|hans|hk|sg))?/|/sr(-(ec|hl|el))?/|/wiki(/|\\?curid=)|/w/|/\\?title=)