
Wikimedia monthly activities meetings/Quarterly reviews/Tech Ops/January 2015
The following are notes from the Quarterly Review meeting with the Wikimedia Foundation's Tech Ops team, January 7, 2015, 10AM - 10:30AM PST.
Present:
- Ori
- RobH
- Toby
- Erik M
- RobLa
- Gabriel
- Alexandros
- Faidon
- Filippo
- Mark B
- Tomasz
- Greg
- Yuvaraj
- Giuseppe
- Lila (until slide 26)
- Damon (from slide 9?)
- Jeff Gage
- Chase
- Other people on the phone bridge?
- Guillaume (taking notes)
Please keep in mind that these minutes are mostly a rough transcript of what was said at the meeting, rather than a source of authoritative information. Consider referring to the presentation slides, blog posts, press releases and other official material.

[slide 1]

[slide 2]
Introduction
[edit]
[slide 3]
- Mark: Yuvi joined from Mobile in the last quarter.
- Mark: More hires are coming.

[slide 4]
What we said
[edit]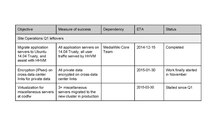
[slide 5]
[slide 6]
- Mark: Goals were not updated at the beginning of the quarter.
- Mark: Varnish4 includes a lot of dev work, and not sufficient immediate benefits, so postponed for now.
[slide 7]
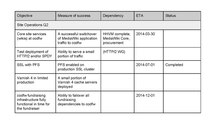
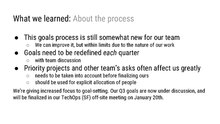
- Lila: The team should limit the goals and make more focused progress. Planned goals should represent more like 80% of the work
- Mark: Agreed, see "what we learned" section later.
What we did
[edit]
[slide 8]

[slide 9]
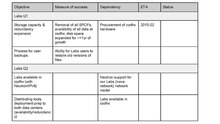
- Mark: Virtualization needed for upcoming SOA.

[slide 10]
[slide 11]
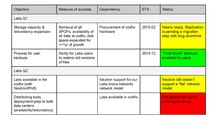
- Mark: We're going to keep labs in Ashburn for now.
- Erik: do we have all the hardware we need for Labs at the moment?
- RobH: codfw labs hardware is nearly identical, just short (roughly) a single virtual worker node (so more than enough for the basic toollabs, but not quite enough for all user labs)

[slide 12]
- Mark: We devoted a significant amount of time to supporting people from other teams. We've experienced a lot more cooperation and a lot less complains about unresponsiveness.
- Mark: needs to offload some of his work because stuff gets dropped; reached out to Arthur. Possibly splitting the team.
- Mark: We are constantly reprioritizing all the tasks every week as stuff comes in

[slide 13]

[slide 14]
What we learned
[edit]
[slide 15]
[slide 16]
Metrics and callouts
[edit]
[slide 17]

[slide 18]
- Mark: This is the same source of data as for the last quarter.

[slide 19]

[slide 20]

[slide 21]

[slide 22]
- Mark: Outages were mostly for misc services (gerrit, bugzilla, misc db)
- Damon: asks about the level of scanning done by iSec.
- MarkB: Chris Steipp has the full results; still awaiting final report from iSec.
- Lila: Any main site outages at all?
- Mark: Yes, a few (3 or 4).
- Erik: These tend to be mostly on the application layer.
- Mark: Usually not on our main wiki/caching infrastructure. eventlogging, misc dbs.
- Lila: For next time, please highlight any service disruption that users can notice. Highlight it, note the duration, and whether it was a degradation / outage etc.
- Mark: We have a large user base (do we include developer tools?). We need to draw the line to define which users to include.
- Lila: It's ok to segment users and prioritize readers & editors
What's next
[edit]
[slide 23]

[slide 24]

[slide 25]
- Mark: Metrics and monitoring will include Watchmouse replacement.

[slide 26]
- Erik: In the next quarter's goals, include the support of other teams explicitly, because it's work we know the Ops team will do. Try to add them into the measures of success.
Asks
[edit]
[slide 27]

[slide 28]
- Damon: Have we talked to the team practices group? (about how to improve project management / processes / procurement approval etc.)
- Mark: Yes, this is ongoing.
- Damon: wants to understand the high-level interaction of the Ops team and get more details, notably by meeting every member of the team as part of his onboarding.
- Erik: There's been a lot of really good work. The formalization of the goal-setting process is underway.
- Damon: agrees. Also wants to figure out how to optimize processes etc. to lower the load on the ops team. Figure out how the organization can better support the Ops team, and how to set priorities in a meaningful way.
- Mark: The Ops team also migrated from RT to Phabricator this quarter, which makes it much easier to collaborate with other teams since now everyone is working in the same space.
- Ori: Cohesion and buy-in of the Ops team appears fantastic. It's a good model to learn from & emulate in the organization.
- Toby: agrees.
[Meeting wraps up.]