
Research on e-books with Wikimedia content
From September 2016 till January 2017, the PublishingLab in Amsterdam researches the potential of curated e-books that are based on (distributed) Wikimedia content from various projects, such as Wikipedia, Wikidata, Wikimedia Commons, Wikibooks, Wikisource, and more.
For more background, see IEG grant request (not selected/awarded).
Process[edit]
Sprint 1: researching existing tools[edit]
What tools are out there?[edit]
In order to situate ourselves in the existing landscape of e-book generating tools, we started gathering information about some of them. What follows is a review of six selected tools, some that are already implemented into specific Wikimedia projects, but also some that are external to the platforms.
Our criteria was:
- cross-platform e-book creation
- experience of assembling the book
- possibility of adding multiple pages
- conversion quality
WSexport[edit]
- http://tools.wmflabs.org/wsexport/tool/book.php,https://wikisource.org/wiki/Wikisource_talk:WSexport
WSexport is only available for Wikisource projects. The tool was developed by user Tpt, who is an administrator of the French Wikisource projects. He has already conducted many tests on this tool (as seen here https://fr.wikisource.org/wiki/Wikisource:Wsexport/Tableau_des_tests). The tool is currently hosted by the Wikimedia labs.
Book Creator on WikiEducator[edit]
Although Wikieducator is not part of the Wikimedia organisation, it is the place where the Book Creator tool was originally implemented. We believe that the tool as it is currently is the same version of the Wikipedia Book Creator which was replaced in 2014. This tool is used by the community to export epubs containing learning material.
EPubExport[edit]
The extension has not been updated since 2010. From the existing documentation, it seems like the possibilities were limited to only being able to generate an epub from one article.
Grabmybooks[edit]
Grabmybooks is an external html to ePub converter. The generated ebooks exclude headers, footers and menus from the export. It is meant to work as a plugin for Chrome and Firefox, but the Chrome extension is not available for now. The tool functions by grabbing the content from the tabs open in the browser, but is not optimised for Wikimedia content. There are still some problems at the structural level of the epub, for example when it comes to tables and the size of the images. Although the tool is not optimised, it is the only one that we found which allows the user to collect articles from all the Wikimedia projects. One of the features that we found interesting, but wasn’t available with the other tools was the personalised book cover.
Pandoc[edit]
Pandoc is the "swiss-army knife" of markup document conversion. Pandoc can generate an epub file from an XML file, but the formatting is not ideal and it cannot embed images in the exported epub.
Sausage Machine[edit]
The Sausage Machine was made by Gottfried Haider during his time working at the PublishingLab. It is a pipeline using markdown language, Pandoc, Git and makefiles. Due to the fact that markdown is a specific instance of markup language, which is different from the mediawiki markup, we ran into some expected difficulties exporting the file. Perhaps with some adjustments, the sausage machine could be an interesting tool to build upon.
Book Creator timeline[edit]
The Book Creator is a tool available on most Wikimedia projects which allows both registered and unregistered users to collect a number of articles and export them as a PDF file. It is currently deprecated with a sign announcing the indefinite state of the existing issues.
As recounted by the last remaining project maintainer, C. Scott Ananian, the Book Creator was an initiative of the PediaPress, an online service for creating customized printed material from Wikimedia content. The partnership was announced in a press release on the 13th of December 2007. The research and development were funded by the Open Society Institute and the product was released as open source to be implemented in any wiki.
"This technology is of key strategic importance to the cause of free education world-wide. " Sue Gardner, former Executive Director of the Wikimedia Foundation, said at the time.
The purpose of the tool was to provide learning assistance for residents of areas without an internet connection. It was first released on the WikiEducator wiki platform, which is based on the same mediawiki software as all the Wikimedia projects, and was the ultimately installed on Wikipedia in 2008.
In 2012 the ePub and ZIM export options were made possible by brainbot technologies, the same software company behind PediaPress.
The Book Creator ran both on the servers of the WMF (Wikimedia Foundation) in Tampa and on the PediaPress servers, connecting printing requests from Wikimedia projects to the publisher. When the WMF moved their servers to a new location, the specifics of the configuration were not known and so the tool could not be replicated again.
However, the efforts of multiple Wikimedians, of which Ananian was a part of, lead to the reissue of the code in 2014 that would comply with the then latest server architecture. Unfortunately, due to lack of technical support the ePub and ZIM functions were dropped.
Since then, not much progress has been made regarding the reinstatement of the additional file formats, although the possibility seems to exist:
“We actually had a great Wikimania this year, with a lot of focus on the "Offline Content Generator" (as the architecture behind Book Creator, PDF export, the Collection extension, etc, is formally named). In fact, we had ZIM export and ePub export capabilities developed during the hackathon. Unfortunately, the code hasn't actually been submitted yet to me/the WMF, so we can't deploy it. :( But it exists, I've seen it running, and for the first time we had more-than-just-me working on OCG.” Scott Ananian
The tool as it was until 2014 is still active on the WikiEducator site.
Sprint 2: Interviews[edit]
Interview with Anja Groten from Hackers and Designers
Interview with Renee Turner, Andre Castro, Manufactura Independente
Sprint 3: Wireframe mockup and presentation at the Wikimedia Netherlands Conference 19.11.2016[edit]
Slides from the presentation:

Speculation on tool requirements[edit]
Situating the tool:
- cross-wiki
- possibility to select specific parts of an article, such as individual objects [paragraphs, images or tables depending on Wikimedia project]
- possibility to visualise editor comments on a paragraph. could turn out to be too difficult to realise from a technical side; an alternative would be to have the option of including a set number of edit comments (last 10/ last 50/ last 100/ whole history)
- multiple languages. whether this would be realised through a translation software or by enabling the possibility to extract material from an alternative language wiki is unsure
- tool should be accessible to both IPs and registered users
- render needs to be fast
- an archive of 'donated' ebooks
- browser extension+platform (for ease of use)
Ideal output:
- cover
- sources
- table of contents
- images
- references
- title
- list of contributors/ authors of the content
- meta data; eg when the article was last edited, how many edits it took to reach this version
- license
Would be nice to have, but not essential:
- possibility to regroup media files according to specific criteria. eg: date added, type of media
- book history: states through which the book has passed
- option to make generated book public or to keep for personal use
Use case scenarios:
- Collecting a user's contributions in an EPUB. Alternative way to archive or quantify the efforts of a Wikimedian
- Book sprints as incentive for edit-a-thons ( possible collaboration with Art+Feminism or GLAM initiatives ) ( interesting reference: v2's initiative of generating ePubs as a way to revitalise the v2 archive https://vimeo.com/96562225 )
- Study material for students/teachers. Students may select their own study material and arrange according to needs
Possible issues:
- multiple platforms
- content is displayed differently so ways of extracting information might differ from wiki project to project
Prototype of the tool[edit]
-
 Add content
Add content -
 Choosing modules
Choosing modules -
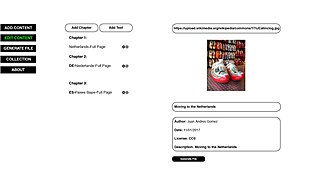 Edit Content
Edit Content -
 Generating a file
Generating a file -
 Collection of epubs
Collection of epubs





The wiki2epub prototype uses the WikiAPI to retrieve data from URLs - which can refer to a Wikipedia Page, a File, a Category, and so on. Let's call them 'objects' and, the data, 'modules'. The idea is to identify the kind of object represented by the URL and display the available modules for it.
An example: if the object is a Wikipedia Page, the available modules would be FullPage, Contributors, Images, Revisions and content in Other Language(s). When the object is a File, modules Image URL would be displayed instead. These modules were defined by the team according to their wish list for the ideal tool.
Once the modules are displayed on the screen, the user/author can select them (multiple module selection is possible). Each module refers to a given action/parameter in the API. For example: the module FullPage would trigger a call using the following action and property
action=parse&page=PageTitle&prop=text
while the module revisions would require
action=query&titles=PageTitle&prop=revisions&rvprop=ids|timestamp|user|comment|content&rvlimit=5&rvdifftotext=prev
Some modules require a second call to the API, like Revisions and Language Links. Also, each module can refer to a specific action and require different properties and parameters to be passed along the call to the API.
It is recommended practice to avoid requesting the same data over and over again and also to minimize the number of requests, so we concatenated modules to be able to make as few API calls as possible.
Next steps[edit]
We would like to have further developed the prototype. Due to time constraints, it was not possible. So here are a few thoughts on possibilities for further development.
The retrieved data needs to be 'unpacked' again and sorted according to the original module and object (displayed in the form of draggable items on the second screen).
Also, saving locally – in the browser's localStorage, for example – which modules and objects were already requested seems to be sensible, as it avoids duplicate calls to the API. If a module and object are already saved, no need to call them again. The exception would be, of course, if the call is a (later) check for an updated version of the content. But this would be done from the saved module (screen Edit Content), not from the Add Content/Choose Modules screen.
The last step in the process (Adding Generated file to a collective collection) has not been thought in detail.
Blog posts[edit]
The research will also be documented through a series of blog posts in the PublishingLab website.
- First sprint: Researching existing tools
- Second sprint: Interviews
- Third sprint: tool speculations and Wikimedia Conference
- Last sprint: wrapping up the wiki research
Link to GitHub[edit]
Participants[edit]
Other Links[edit]
- https://www.mediawiki.org/wiki/Collection_Extension_2
- https://meta.wikimedia.org/wiki/Wikipedia_Collections
- http://www.adamhyde.net/some-publishing-systems-i-have-developed/
-
 Wiki2epub GIF
Wiki2epub GIF
