
IP Editing: Privacy Enhancement and Abuse Mitigation/Improving tools/nl
Achtergrond
Ons doel voor dit project is tweeledig:
- Ten eerste, om onze projecten te beschermen tegen vandalisme, lastigvallen, sockpuppels, langdurige misbruik vandalen, desinformatiecampagnes en ander verstorend gedrag.
- Ten tweede, om onze niet geregistreerde redacteurs te beschermen tegen vervolging, intimidatie en misbruik door hun IP-adressen niet te publiceren.
Op basis van onze gesprekken op de overlegpagina van het project en elders, hebben we gehoord van de volgende manieren waarop IP-adressen worden gebruikt op onze projecten:
- IP-adressen zijn nuttig bij het zoeken naar "nabijgelegen" redacteurs - die van hetzelfde of een nabijgelegen IP-bereik bewerken
- Ze worden gebruikt om de bijdragegeschiedenis van een niet-geregistreerde redacteur op te zoeken
- IP-adressen zijn nuttig bij het vinden van cross-wiki-bijdragen
- Ze zijn handig om uit te zoeken of iemand probeert te bewerken vanaf een VPN of via Tor
- Ze zijn nuttig om de locatie van een redacteur te vinden, inclusief details zoals hun universiteit/bedrijf/gouvernementele instantie
- IP-adressen worden gebruikt om te zien of een IP-adres is gekoppeld aan een bekende langdurige misbruiker (LTA)
- Ze worden soms gebruikt om specifieke misbruikfilters in te stellen om specifieke soorten spam proberen te voorkomen.
- IP-adressen zijn belangrijk voor het blokkeren van een bereik
Een aantal van deze workflows komt in actie wanneer we proberen te zien of twee gebruikersaccounts door dezelfde persoon worden gebruikt, ook wel sockpuppetdetectie genoemd. Het gebruik van IP-adressen om detectie hiervan uit te voeren is een gebrekkig proces. IP-adressen worden steeds dynamischer met de toename van het aantal mensen en apparaten dat online komt. IPv6-adressen zijn ingewikkeld en bereiken zijn moeilijk te achterhalen. Voor de meeste nieuwkomers lijken IP-adressen een stel schijnbaar willekeurige getallen die niet kloppen, moeilijk te onthouden en moeilijk te gebruiken zijn. Het kost nieuwe gebruikers veel tijd en moeite om te wennen aan het gebruik van IP-adressen voor blokkerings- en filterdoeleinden.
Ons doel is om onze afhankelijkheid van IP-adressen te verminderen door nieuwe hulpmiddelen te introduceren die verschillende informatiebronnen gebruiken om overeenkomsten tussen gebruikers te vinden. Om IP-adressen uiteindelijk te maskeren zonder onze projecten negatief te beïnvloeden, moeten we zichtbare IP-adressen overbodig maken voor het proces. Dit is ook een kans om krachtigere hulpmiddelen te bouwen die helpen bij het identificeren van slechte actoren.
Voorgestelde te bouwen hulpmiddelen
We willen het voor gebruikers eenvoudiger maken om de informatie die ze nodig hebben uit IP-adressen te verkrijgen om het werk te doen dat ze nodig hebben. Om dat te doen, zijn er drie nieuwe hulpmiddelen/functies waar we aan denken.

1. IP-informatiefunctie
Deze functie is een werk in uitvoering. Voortgang IP-infofunctie bekijken
Er zijn enkele kritieke stukjes informatie die IP-adressen bieden, zoals locatie, organisatie, mogelijkheid om een Tor/VPN-knooppunt te zijn, rDNS, vermeld bereik enz. Als een redacteur deze informatie over een IP-adres wil zien, gebruikt hij nu een externe hulpmiddel of zoekmachine om die informatie te extraheren. We kunnen dit proces vereenvoudigen door die informatie beschikbaar te stellen aan vertrouwde gebruikers op de wiki. In een toekomst waarin IP-adressen worden gemaskeerd, wordt deze informatie nog steeds weergegeven voor gemaskeerde gebruikersnamen.
Een zorg die we tot nu toe hebben gehoord van gebruikers met wie we hebben gesproken, is dat het niet altijd gemakkelijk is om te zien of een IP-adres afkomstig is van een VPN of op een zwarte lijst staat. Zwarte lijsten zijn kwetsbaar - sommige zijn niet erg actueel, andere kunnen misleidend zijn. We zijn geïnteresseerd om te horen in welke scenario's het nuttig voor u zou zijn om te weten of een IP-adres van een VPN is of tot een zwarte lijst behoort en hoe u die informatie nu kunt opzoeken.
Voordelen:
- Dit zou de noodzaak voor gebruikers om IP-adressen te kopiëren en plakken in externe hulpmiddelen en om de benodigde informatie te extraheren, wegnemen.
- Wij verwachten dat dit ook de tijd die wordt besteed aan het ophalen van de gegevens aanzienlijk zal verminderen.
- Op de lange termijn zou het helpen om onze afhankelijkheid van IP-adressen te verminderen.
Risico's:
- Op basis van de implementatie lopen we het risico dat we informatie over IP's blootstellen aan een grotere groep mensen dan alleen de beperkte groep gebruikers die zich nu bewust zijn van hoe IP-adressen werken.
- Afhankelijk van welke onderliggende dienst we gebruiken om de details over een IP te verkrijgen, is het mogelijk dat we informatie niet kunnen vertalen, maar informatie in het Engels moeten tonen.
- Er bestaat het risico dat gebruikers het verkeerd begrijpen als de organisatie/school achter de bewerking staat, in plaats van het individu dat de bewerking heeft gedaan.
2. Het vinden van vergelijkbare editors
Om sockpuppets (en niet-geregistreerde gebruikers) te detecteren, moeten redacteuren zich tot het uiterste inspannen om erachter te komen of twee gebruikers dezelfde persoon zijn. Dit omvat het vergelijken van de bijdragen van de gebruikers, hun locatiegegevens, bewerkingspatronen en nog veel meer. Het doel van deze functie is om dit proces te vereenvoudigen en enkele van deze vergelijkingen te automatiseren die zonder handmatige arbeid kunnen worden gemaakt. Dit zou worden gedaan met behulp van een machine learning-model dat accounts kan identificeren die vergelijkbaar gedrag vertonen. Het model zal voorspellingen doen over inkomende bewerkingen die zullen worden weergegeven aan checkusers (en mogelijk andere vertrouwde groepen) die vervolgens in staat zullen zijn om die informatie te verifiëren en passende maatregelen te nemen.
We zouden mogelijk ook een manier kunnen hebben om twee of meer niet-geregistreerde gebruikers te vergelijken om overeenkomsten te vinden, inclusief kijken of ze bewerken vanaf IP-adressen of IP-bereiken in de buurt. Een andere mogelijkheid hier is om de tool in staat te stellen enkele van de blokkeringsmechanismen die we gebruiken te automatiseren, zoals automatische bereikdetectie en het voorstellen van bereiken om dienovereenkomstig te blokkeren.
Een hulpmiddel als dit heeft veel mogelijkheden - van het identificeren van individuele slechte editors tot het ontdekken van geavanceerde ringen van sockpuppets. Maar er is ook het risico dat legitieme accounts worden blootgelegd die om verschillende redenen hun identiteit geheim willen houden. Dit maakt dit project lastig. Wij willen van u horen wie dit hulpmiddel moet gebruiken en hoe we de risico's kunnen verminderen.
Met de hulp van de gemeenschap kan een dergelijke functie zich ontwikkelen om functies te vergelijken die redacteurs nu gebruiken bij het vergelijken van redacteurs. Een mogelijkheid is ook het opvoeden van een machine learning-model om dit te doen (zoals ORES problematische bewerkingen detecteert).
Hier is een mogelijkheid voor hoe een dergelijke functie in de praktijk er uit zou kunnen zien:
-
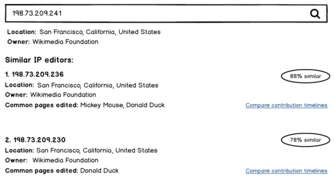 Zoek van vergelijkbare editors met IP's
Zoek van vergelijkbare editors met IP's -
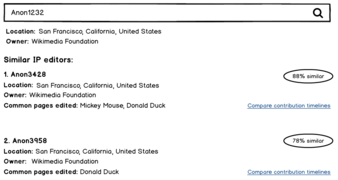 Zoek van vergelijkbare redacteurs met gemaskeerde IP's
Zoek van vergelijkbare redacteurs met gemaskeerde IP's


Voordelen:
- Een dergelijk hulpmiddel zou de tijd en inspanning van onze functionarissen aanzienlijk verminderen om slechte editors op onze projecten te vinden.
- Dit hulpmiddel kan ook worden gebruikt om gemeenschappelijke bereikt tussen bekende slechte editors te vinden om het blokkeren van IP-bereiken gemakkelijk te maken.
Risico's:
- Als we Machine Learning gebruiken om sockpuppets te detecteren, moet dit zeer zorgvuldig worden gecontroleerd en gecontroleerd op vooroordelen in de trainingsgegevens. Voor het te veel vertrouwen op de similarity-indexscore moet worden gewaarschuwd. Het is absoluut noodzakelijk dat menselijke beoordeling deel uitmaakt van het proces.
- Een gemakkelijker toegang tot informatie zoals locatie kan het soms gemakkelijker maken, niet moeilijker, om identificeerbare informatie over iemand te vinden.
3. Een database voor het documenteren van langdurige misbruikers
Langdurige misbruik door vandalen worden handmatig gedocumenteerd op de wiki's, als het al wordt gedocumenteerd. Dit omvat het opschrijven van een profiel van hun bewerkingsgedrag, artikelen die ze bewerken, indicatoren voor het herkennen van hun accounts, het opnemen van alle IP-adressen die ze gebruiken en meer. Met tal van pagina's die de IP-adressen omvatten die door deze vandalen worden gebruikt, is het steeds meer een gigantisch taak om bij behoefte relevante informatie te zoeken en te vinden, indien deze beschikbaar is. Een betere manier om dit te doen is een database op te bouwen die de langdurige misbruikers documenteert.
Een dergelijk systeem zou het gemakkelijk maken om cross-wiki te zoeken naar gedocumenteerde vandalen die aan de zoekcriteria voldoen. Uiteindelijk kan dit mogelijk worden gebruikt om gebruikers automatisch te markeren wanneer blijkt dat hun IP's of bewerkingsgedrag overeenkomen met die van bekende langdurige misbruikers. Nadat de gebruiker is gemarkeerd, kan een beheerder de nodige actie ondernemen als dat gepast lijkt. Er is een open vraag of dit openbaar of privé moet zijn of iets daartussenin. Het is mogelijk om machtigingen te hebben voor verschillende gebruiksniveaus voor lees- en schrijftoegang tot de database. We willen van u horen wat volgens u het beste zou werken en waarom.

Kosten:
- Zo'n database zou leden van de gemeenschap nodig hebben om deel te nemen aan het vullen ervan met de nu bekende langdurige misbruikers. Dit kan voor sommige wiki's een aanzienlijke hoeveelheid werk zijn.
Voordelen:
- Cross-wiki zoeken naar gedocumenteerde langdurige misbruikers zou een enorm voordeel zijn ten opzichte van het huidige systeem, waardoor het werk van patrollers lichter zou kunnen worden.
- Het geautomatiseerd markeren van potentieel problematische editors op basis van bekende bewerkingspatronen en IP's zou in veel workflows van pas komen. Het zou beheerders in staat stellen om oordelen en acties te maken op basis van deze markeringen.
Risico's:
- Bij het bouwen van zo'n systeem zouden we goed moeten nadenken over wie toegang heeft tot de databasegegevens en hoe we deze kunnen beveiligen.
Deze ideeën bevinden zich in een zeer vroeg stadium. We hebben uw hulp nodig bij het brainstormen over deze ideeën. Wat zijn de kosten, baten en risico's die we misschien over het hoofd zien? Hoe kunnen we deze ideeën verbeteren? We horen graag van u op de overlegpagina.
Bestaande hulpmiddelen gebruikt door editors
On-wiki hulpmiddelen
- CheckUser: CheckUser geeft een gebruiker met een checkuser vlag toegang tot vertrouwelijke gegevens die zijn opgeslagen over een gebruiker, IP-adres of CIDR-bereik. Deze gegevens omvatten IP-adressen die door een gebruiker worden gebruikt, alle gebruikers die hebben bewerkt vanaf een IP-adres of -bereik, alle bewerkingen vanaf een IP-adres of -bereik, User agent-tekenreeksen en X-Forwarded-For-headers. Meest gebruikt voor het detecteren van sockpuppets.
- Geef checkusers toegang tot gebruikers die meer dan 50 accounts hebben voor hetzelfde e-mailadres. Het bestaan daarvan werd bevestigd in phab:T230436 (hoewel de taak zelf irrelevant is). Hoewel dit geen directe invloed heeft op de privacy van IP-gegevens, kan het het effect van moeilijker misbruikbeheer enigszins verzachten.
Projectspecifieke hulpmiddelen (inclusief bots en scripts)
Geef aan op welk project het hulpmiddel wordt gebruikt, wat het doet en voeg indien mogelijk een link toe
Externe hulpmiddelen
ToolForge hulpmiddelen
- Intersect contribs - bekijken door een aantal gebruikers bewerkte dezelfde pagina's
- WHOIS en reverse DNS
- Editor interaction analyser – Analyseer interacties tussen twee of drie gebruikers – activiteit op dezelfde pagina's, tijdens hetzelfde tijdstip, enz.
- IPCheck: Hiermee kunt u informatie over een IP-adres opzoeken, inclusief of het een proxy, tor-node of potentiële VPN is.
- GUC – Globale gebruikersbijdragen voor elke gebruiker.
- Reverse DNS voor een IP-bereik
Third-party hulpmiddelen
- IP-adres blokkereren: http://www.nirsoft.net/countryip/cz.html
- User agent opzoeken: http://www.useragentstring.com/
- Nmap
- Spamhaus lijsten en XBL (Zwarte lijst met exploits)
- Talos – IP reputatie (voornamelijk voor e-mail spam)