
IP-redigering: Bättre integritetsskydd samt hantering av vandalism/Förbättrade verktyg
Bakgrund
Vårt mål för det här projektet är tvåfaldigt:
- Först, för att skydda våra wikier från vandaler, trakasserier, marionetter, återkommande problemanvändare, desinformationskampanjer och andra beteende som stör redigerandet av wikin.
- Dessutom, att skydda oregistrerade användare från förföljelse, trakasserier och attacker genom att publicera deras IP-adresser.
Baserat på våra konversationer på projektdiskussionssidan och annorstädes, har vi följande lista över sätt som kännedomen om en IP-adress är används på våra wikier:
- IP-adresser är användbara för att hitta närliggande användare – från samma IP eller IP-intervall
- De används för att kolla upp bidragshistoriken från en oregistrerad användare
- De är användbara för att hitta bidrag över olika wikier
- För att se om försöker redigera från en VPN eller via TOR
- För att se varifrån någon redigerar, inklusive saker som universitet/skola/företag/myndighet
- För att se om en IP-adress är kopplad till en återkommande problemanvändare
- För särskilda redigeringsfilter som upptäcker viss typ av spam
- För intervallblockeringar
Ett antal av dessa arbetsflöden blir relevanta när vi försöker se om två konton används av en och samma användare, en marionettkontroll. Att använda IP-adresser för att kontrollera marionetter har sina problem: IP-adresser blir allt mer dynamiska i och med att fler personer och enheter kommer online. IPv6 är komplicerade och intervallerna svåra att lista ut. För de flesta nykomlingar är IP-adresser en samling till synes slumpartade nummer som saknar sammanhang, är svåra att minnas och svåra att använda. Det tar betydande tid och ansträngning för nya användare att vänja sig vid IP-adresser för blockering och filtrering.
Vårt mål är att reducera vårt behov av IP-adresskännedom genom att introducera nya verktyg som använder varierande informationskällor för att hitta likheter mellan användare. För att kunna maskera IP-adresser utan att skada projekten måste vi göra synliga IP-adresser överflödiga i processen. Detta är också en möjlighet att bygga kraftiga verktyg för att identifiera konton som är ute efter att skada projekten.
Föreslagna idéer för verktyg att bygga
Vi vill att det skall bli enklare för användare att skaffa informationen de behöver från IP-adresser för att kunna göra sitt arbete. För att kunna göra det, funderar vi på tre ny verktyg.

1. IP-informationsverktyget
This feature is currently a work in progress. To follow along, please visit: IP Info Feature.
Det finns vissa bitar information som en IP-adress ger, så som plats, organisation, möjlighet att det är en TOR/VPN-nod, rDNS, listat intervall och så vidare. I dag, för att en wikimedian skall kunna se den informationen, måste de använda ett externt verktyg eller en sökmotor för att hitta den. Vi kan förenkla den processen genom att visa informationen för pålitliga användare. I en framtid där IP-adresser är maskerade skulle den här informationen fortsätta att visas för de maskerade IP-adresserna.
En sak vi har hört från användare som vi har pratat med är att det inte alltid är enkelt att veta om en IP kommer från ett VPN eller är svartlistad. Svartlistningar är knepiga – vissa är inte uppdaterade, andra kan vara missvisande. Vi är intresserade av att höra i vilka scenarier det skulle vara hjälpsamt att veta om ett IP kommer från ett VPN eller hör till svartlistade IP-nummer och hur du går till väga för att kontrollera det i dagsläget.
Fördelar:
- Detta skulle ta bort behovet att kopiera och klistra in IP-adresser i externa verktyg för att få fram nödvändig information.
- Vi tror att detta kommer att innebära en betydande minskning för tiden som används för att få fram data.
- I längden kommer det minska vårt beroende av IP-adresser, som är svåra att förstå.
Risker:
- Vi riskerar att visa information om IP-adresser till en större grupp användare än bara den lilla grupp som i dagsläget är medvetna om hur IP-adresser fungerar.
- eroende på vilken service vi använder för att få fram detaljerna, är det möjligt att vi inte kommer att ha möjlighet att få fram översatt information, utan att delar av den är på engelska.
- Det finns en risk att personer missförstår och tolkar det som att organisationen ligger bakom, snarare än en individ på en IP-adress kopplad dit.
2. Hitta liknande användare
För att hitta marionetter (och oregistrerade användare), måste man i dag gå igenom en avancerad process för att lista ut om två användare har samma person bakom tangentbordet. Det inkluderar att jämföra användarnas bidrag, deras platsdata, redigeringsmönster och mycket annat. Målet för det här verktyget är att förenkla den här processen och automatisera en del jämförelser som kan göras utan manuell hantering.
This would be done with the help of a machine learning model that can identify accounts demonstrating a similar behavior. The model will be making predictions on incoming edits that will be surfaced to checkusers (and potentially other trusted groups) who will then be able to verify that information and take appropriate measures.
Vi skulle möjligtvis också kunna jämföra två eller fler oregistrerade användare för att hitta likheter. En annan möjlighet är ett verktyg för att automatisera några av de blockeringsmekanismer vi använder – som automatisk IP-intervallsigenkänning och att rekommendera intervaller att redigera utifrån det.
A tool like this holds a lot of possibilities—from identifying individual bad actors to uncovering sophisticated sockpuppeting rings. But there is also a risk of exposing legitimate sock accounts who want to keep their identity secret for various reasons. This makes this project a tricky one. We want to hear from you about who should be using this tool and how can we mitigate the risks.
Med hjälp av gemenskapen skulle ett sådan verktyg kunna utvecklas till att jämföra de saker som vandalbekämpare i dag använder för att jämföra redigeringar. En möjlighet är också att träna en maskininlärningsmodell att göra detta (jämför med hur ORES känner igen problematiska redigeringar).
Här är ett alternativ för hur ett sådan verktyg skulle kunna se ut ui praktiken:
-
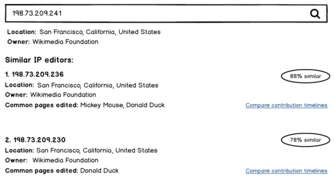 Hitta användare med liknande IP-adresser
Hitta användare med liknande IP-adresser -
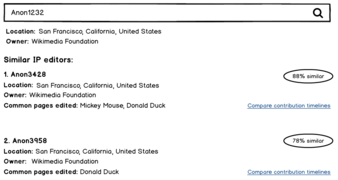 Hitta motsvarande användare med maskerade IP-adresser
Hitta motsvarande användare med maskerade IP-adresser


Fördelar:
- Ett sådant verktyg skulle kraftigt minska tiden och ansträngningen som krävs för att jaga vandaler, marionetter och andra användare som förstör projekten.
- Det skulle också kunna användas för att hitta gemensamma IP-intervaller mellan kända problemanvändare för att göra det enklare med intervallblockeringar.
Risker:
- Om vi använder maskinigenkänning för att hitta marionetter måste det granskas mycket noga och kontrolleras för partiskhet i träningsdatan. Vi måste varna mot att förlita sig för mycket på verktygets likhetsbedömning. Det är centralt att en mänsklig genomgång är en del av processen.
- Enklare tillgång till information såsom platsdata kan ibland göra det enklare, inte svårare, att hitta identifierbar information om någon.
3. En databas för att dokumentera återkommande problemanvändare
Återkommande problemanvändarvandaler är manuellt dokumenterade i wikin, om alls. Detta kan inkludera en profil om redigeringsmönster, artiklar de redigerar, indikationer för hur man känner igen deras marionetter, lista deras IP-adresser och så vidare. Med många sidor som täcker de IP-adresser som används av de här vandalerna är det – om informationen finns sparad – ett stort jobb att gå igenom den och hitta vad som behövs. Ett bättre sätt att göra det vore att ha en databas för att dokumentera problemen.
Ett sådant system skulle kunna förenkla sökning över olika wikier för dokumenterade vandaler som matchar vissa sökkriterier. Slutligen skulle det kanske kunna användas för att automatiskt flagga användare när deras IP:er eller redigeringsmönster matchar kända återkommande problemanvändare. Efter att användaren har flaggats, skulle en administratör kunna undersöka saken och agera om så är rimligt.

Kostnad:
- En sådan databas skulle kräva att gemenskapen deltog i att bygga upp den med kända problemanvändare. Detta skulle kunna innebära betydande arbete för vissa wikier.
Fördelar:
- En sökning över flera wikier för kända återkommande problemanvändare skulle kunna vara klart överlägset det nuvarande systemet, och minska arbetsbördan för vandalbekämpare.
- Automatiskt flaggning av potentiella problemanvändare baserat på kända mönster och IP:er skulle kunna förstärka flera arbetsflöden. Det skulle tillåta administratörer att göra bedömningar och gå till handling baserat på föreslagna flaggningar.
Risker:
- Om vi bygger ett sådant system skulle vi behöva lista ut vem som har tillgång till det och hur vi säkrar innehållet.
Alla dessa idéer är på ett mycket tidigt stadium. Vi behöver er hjälp med att fundera kring dem. Vad är vissa kostnader, fördelar och risker vi kan ha missat? Hur kan vi förbättra dem? Vi skulle gärna få återkoppling på diskussionssidan.
Existerande verktyg som vi använder
Verktyg på wikier
- IP-kontrollantverktyget: IP-kontrollantverktyget tillåter en användare med tillgång till det att se data som har sparats, som IP-adress eller CIDR-intervall. Denna datan inbegriper bland annat IP-adress, alla användare som redigerat från IP-adressen eller intervallet och user agent-data. Huvudsakligen används det för att hitta marionetter.
- Låt IP-kontrollanter ha tillgång till vilka använder som har fler än femtio konton på samma IP-adress. Att sådana finns konfirmerades i phab:T230436 (i sig in relevant här). Även om det inte påverkar IP-integriteten direkt, skulle det i någon mån kunna kompensera för effekterna av hårdare kontroll av vandalbekämpningen.
Projektspecifika verktyg (inklusive botar och skript)
Specificera vänligen vilket projekt verktyget används på, vad det gör och inkludera om möjligt en länk
External verktyg
ToolForge-verktyg
- Intersect contribs – listar användares bidrag för jämförelse
- WHOIS and reverse DNS
- Editor interaction analyser - analyserar interaktioner mellan två eller tre personer – redigeringar på samma sidor, vid samma tidpunkter och så vidare
- IPCheck: För att kolla upp information om en IP-adress inklusive om den är en proxy, TOR-nod eller möjlig VPN.
- GUC - Globala användarbidrag för vald användare.
- Reverse DNS for a range – omvänd DNS för ett intervall
Tredjepartsverktyg
- Stora IP-adressblockeringar: http://www.nirsoft.net/countryip/cz.html
- Kolla upp user-agent-info: http://www.useragentstring.com/
- Nmap
- Spamhaus lists and XBL (exploitssvartlistning)
- Talos - IP-anseende (huvudsakligen för mejlspam)