
FindingGLAMs/White Paper/AROUND
A White Paper as Guidance for Future Work
developed as part of the FindingGLAMs project
Case Study 7: AROUND – Advance Return Of User-generated New Data[edit]
-
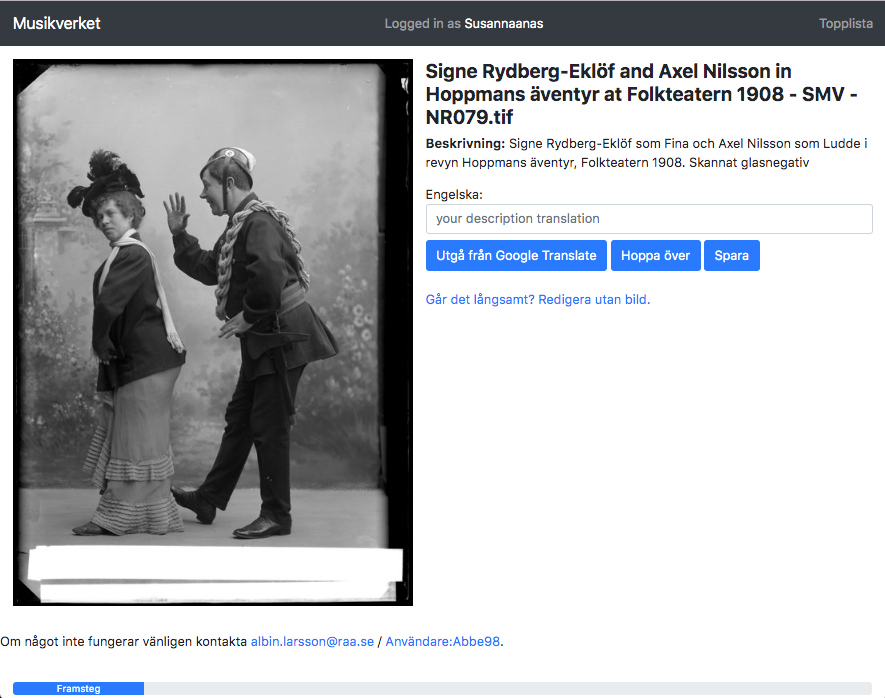 The Roundtripping translation tool built for the Swedish Performing Arts Agency.
The Roundtripping translation tool built for the Swedish Performing Arts Agency.

Key facts[edit]
Time: November 2018 – June 2019
Organizations involved: Swedish National Heritage Board, Swedish Performance Arts Agency, Nationalmuseum, Nordic Museum
Wikimedia/free knowledge communities involved: Wikimedia Sverige
Keywords: GLAM, Wikimedia Commons, metadata, crowdsourcing
Key conclusions[edit]
- There is an interest among cultural heritage institutions in extracting enriched metadata from Wikimedia Commons.
- Extracting and ingesting this data is not easy for most organizations.
- Lack of trust and verifiability is a common obstacle to ingesting data from volunteer contributors.
- Insufficient technical resources are an obstacle to ingesting data from other institutions and from authority files.
Background[edit]
Wikimedia Commons contains a lot of material shared by cultural heritage institutions. When included in Wikipedia articles in many languages, this material can reach a larger and more diverse audience than on the GLAM website. Additionally, the Wikimedia audience has the ability to edit the material, improving the descriptions and translating them into other languages, categorizing the files, pointing out errors, and so on. Those additions, however, only benefit other Wikimedians, as they are not reflected back at the source – in the GLAM’s own database. This is a net loss for the cultural heritage institutions that miss out on the fruits of the work of volunteers around the world. Instead, they could ingest the improved metadata back into their collection management systems, which would not only enrich their collections, but also send a strong signal to Wikimedia editors that their work is noticed and valued. This process is called data roundtripping.
A research project undertaken in mid-2019 by Wikimedia Deutschland, focusing on how cultural heritage institutions use Wikidata, also explored the question of ingesting data from Wikidata into the institutions' internal systems.[1] A significant proportion of the participants in the study, representing different types of GLAMs mostly in Europe, were positive to the idea, mentioning that the data on Wikidata might be of better quality than the institutions' data. However, despite the broad interest, only a few institutions were found to have implemented data roundtripping solutions of some sort.
This case study is a short summary of a project exploring the interest in, and possible practical implementations of, data roundtripping that was carried out by the Swedish National Heritage Board with partial funding from the European Union within the Europeana Common Culture project. See the project page on Meta-Wiki for the full documentation.
Problem[edit]
The project aimed at researching to which degree cultural heritage institutions can use the Wikimedia platforms to 1) engage contributors to actively interact with their content, and 2) create the data created by Wikimedians to enrich their own data repositories.
Implementation[edit]
The project was initialized with a research stage to get an insight into how GLAMs use third-party metadata in their collection management systems, consisting of a survey and a set of qualitative interviews.
Three pilot studies were then designed and carried out in collaboration with three Swedish GLAMs.
The Swedish Performing Arts Agency pilot focused on translating photo descriptions from Swedish into English. A dedicated tool was developed, in which users were presented with photographs from the Swedish Performing Arts Agency's collection on Wikimedia Commons, and could translate the descriptions either from scratch or by improving the output from Google Translate. The edits were saved directly in Wikimedia Commons. The results of this project were not ingested into the GLAM's database due to quality issues.
The Nationalmuseum pilot focused on retrieving authority ID's from Wikidata into the museum's collection management system. The pilot targeted the items of artists represented in the museum's collections, identified by the Nationalmuseum Sweden artist ID property (P2538), and the ID's to import included the Wikidata ID, KulturNav, VIAF and ULAN.
The Nordic Museum pilot made use of Structured Data on Commons and focused on adding depicts (P180) statements to fashion paintings from the museum's collection. A dedicated tagging tool was developed, limited to a set of controlled vocabulary, to make this task easy for the users.
Outcome[edit]
Ingesting third-party contributions into the institutional data repositories is not easy to implement for GLAMs, even if they are generally interested in it. Issues of trust and verifiability are notable obstacles cited when discussing crowdsourced contributions. On the technical side, there's a great variety of content management systems used by cultural heritage institutions, which affect how easily such ingestion can be done and whether external assistance is necessary.
Future[edit]
The Wikimedia platforms are an important part of the global knowledge landscape. Cultural heritage institutions around the world are becoming increasingly more interested in sharing their materials there, which is why further research in the area of third-party data ingestion is needed. Best practices need to be developed on how to manage third party information and communicate its provenance to end users. Efficient validation processes for crowdsourced information are needed in order to ensure the verifiability and quality of information in the institutions' content management systems. On the technical side, content management systems should become more flexible in allowing easy metadata ingestion, and open data exchange standards should be developed and/or implemented more widely.