
FindingGLAMs/White Paper/ORDER
A White Paper as Guidance for Future Work
developed as part of the FindingGLAMs project
Case Study 6: ORDER – Organized, Reusable Data Enhanced in Relationships[edit]
-
 Hauptstrasse in Ochsenfurt, Germany (1901). Sigurd Curman.
Hauptstrasse in Ochsenfurt, Germany (1901). Sigurd Curman.

Key facts[edit]
Time: January – February 2020
Organizations involved: National Museum of Science and Technology
Wikimedia/free knowledge communities involved: Wikimedia Sverige
Keywords: Structured Data on Commons, metadata
Key conclusions[edit]
- Structured Data on Commons is mature enough to be interesting to uploaders of GLAM collections.
- SDC makes editing Wikimedia Commons more accessible to GLAM staff without previous experience.
- SDC cannot be edited directly from the popular upload tools, requiring editors to either write their own scripts or use any of the small volunteer-developed tools with limited scope.
- Being able to work with SDC directly in the metadata processing and file upload stage is crucial if we want to rapidly increase the number of files using SDC.
Background[edit]
The National Museum of Science and Technology (Tekniska museet) is a Swedish museum that expressed interest in collaborating with Wikimedia Sverige. They requested help with uploading one of their photo collections, comprising about 500 files by the Swedish architecture historian Sigurd Curman, to Wikimedia Commons. We had had a dialog about the possibility of this project for at least a year, with one museum staff member agreeing to map the photographs’ metadata (such as depicted places and architectural objects) to Wikimedia Commons categories. Early in 2020, the selection of the files and the mapping of the metadata was finalized by the museum and the collection was ready to upload.
Structured Data on Commons (SDC) is information about media files on Wikimedia Commons that can be parsed by humans and machines alike. This is what distinguishes it from the default way of describing media files using wikitext, which has been in use since the advent of Wikimedia Commons. The description is fully free-form which, while offering almost unfettered flexibility to the editor, does not easily lend itself to structure. It is formatted using wikitext, a markup language used across the Wikimedia platforms – yet another technology that newcomers have to learn at least the basics of in order to contribute efficiently.[1] Over the years, editors have developed hundreds of templates of varying complexity, as well as written and unwritten standards for how different sorts of media files should be described. This causes problems for both editors, who can easily and unwittingly deviate from the usual way things are done, and users who want to query Wikimedia Commons using the contents of the wikitext descriptions (which, due to the multitude of existing templates, are not trivial to parse).
From the perspective of years upon years of free-form file descriptions, Structured Data on Commons offers a revolutionary way of describing and querying the millions of resources collected by Wikimedians. Each piece of information, such as the date of creation of a file, or the camera coordinates, belongs in a dedicated field. Furthermore, SDC is tightly coupled to Wikidata; rather than entering an artist’s name or describing what objects are depicted in a photo, the user only has to link to their Wikidata items. This in turn facilitates multilinguality, as Wikidata items can have labels in many different languages. Wikimedia Commons users can see them in the language of their choice, benefitting from the work of Wikidata editors. Thus, SDC saves time for both file uploaders and users of Wikimedia Commons.
We had not previously worked with SDC in a systematic way, so this project provided us with a valuable opportunity to explore this area and its suitability for future GLAM uploads.
Problem[edit]
The problem this project tried to solve was implementing Structured Data on Commons in a typical GLAM image upload using the available tools and documentation. By doing that, our goal was to get a realistic overview of the existing SDC infrastructure, both in terms of SDC itself (maturity and usefulness of the structured data layer in Wikimedia Commons, which at the time of writing is under development) and the tools available to editors, their strength and weaknesses.
The Curman collection was particularly suitable for such a project due to its consistency. All the photos are authored by the same photographer and have the same copyright status, making the collection a good candidate to test adding structured data in batches. At the same time, its relatively small size – only 500 images – makes it possible to work with structured data using the visual tools available as Wikimedia Commons scripts or gadgets. It also makes it attractive to volunteer editors wishing to make manual SDC edits on an ad-hoc basis. A collection of several thousand items – not unusual in our work with GLAMs – would require more efficient tools and processes.
Implementation[edit]
The material provided by the National Museum of Science and Technology consisted of 558 TIFF files with accompanying metadata supplied in a spreadsheet. We used OpenRefine to process the metadata for both Wikidata and Wikimedia Commons, and Pattypan to upload the files to Wikimedia Commons. The process did not differ from that outlined in Case Study 4 and thus does not need to be elaborated upon in more detail here. Instead, we will focus on the SDC work which was done after uploading the files to Wikimedia Commons.
Neither OpenRefine nor Pattypan currently support Structured Data on Commons. This was an important factor in our choice of workflow and tools. There are, to our best knowledge, no tools or applications for uploading files to Wikimedia Commons that offer SDC integration. We thus faced two alternatives: writing our own tools – either for uploading files together with SDC statements or, more simply, to interact with SDC in existing files via the API – or surveying and using the available tools. The advantage of the latter solution was that it would give us a good overview of what is available to regular users, which we would need anyway before embarking on tool development on our own.
Add to Commons Descriptive Claims (ACDC) is a gadget to add SDC statements to a set of files.[2] It can be used on a manually defined list of files, on the contents of a category or on a PagePile (list of files generated by one of several search tools such as Petscan).[3][4] The tool was developed and is maintained by a volunteer. It does not have a predefined list of statements; users are free to add any statements currently supported by SDC, including qualifiers. We used this tool to add the following SDC statements:
- creator → Sigurd Curman, with the qualifier object has role → photographer,
- copyright status → public domain, with the qualifier determination method → 50 years after creation of (non-artistic) photographic image
- copyright license → Public Domain Mark
Adding these statements was straightforward. However, the changes were applied at a very slow rate, taking several hours for the whole batch of 500 files being processed.
The SDC Tool is a user script to add SDC statements to a set of files.[5] It can be used on categories, galleries and search results. Just like the Descriptive Claims tools, it was developed by a volunteer. The main difference from Descriptive Claims is that it only allows users to add statements from a predefined list, which in February 2020 consisted of: depicts, depicted part, collection, significant event, location of creation, and location of the point of view. We used this tool to add the following SDC statements:
- collection → National Museum of Science and Technology
We did not find more functionalities in this tool than the Descriptive Claims tool had to offer. While the execution was noticeably faster, the limited number of statements available makes this tool much less flexible. Advanced users can copy the source code to their own user space and modify the tool in accordance with their needs, but this option might not be accessible to everyone.
Outcome[edit]
-
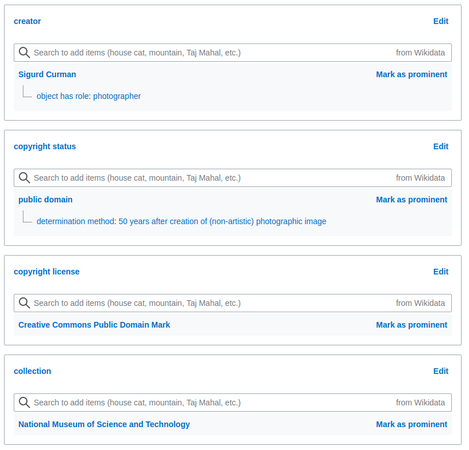 Structured Data in one of the photographs included in the upload.
Structured Data in one of the photographs included in the upload.

We uploaded 558 photographs to Wikimedia Commons[6] as well as created the same number of Wikidata items.[7] Each file on Wikimedia Commons is linked to the corresponding Wikidata item, and the other way round. We added 4 structured data statements to each of the files, as detailed above.
The selection of statements to add was one of the big considerations of this project.The provided metadata contained information that would have been interesting to add but that we ended up omitting, such as:
- The dates the photos were taken. At the point of working with the Curman collection, adding time and date statements had not been implemented in the UI and was thus not possible for Wikimedia Commons editors.[8] Currently (February 2020) it is possible to add time and date statements directly via the API, even though users are prevented from editing them due to the data type not being supported in the UI.
- File-specific data, i.e. data not common for the whole collection. This includes the aforementioned dates, but also information about where the photo was taken and what it depicts. This information is present in the metadata, and was included in the form of categories, as mapped by the museum staff, so it was not lost. A possible workflow to add this information as SDC based on the categories is as follows:
- Create a Pagepile in Petscan from the cross-section of the upload category (Media_contributed_by_Tekniska_museet:_2020-02) and the desired content category, e.g. Adlerstraße_(Nuremberg)
- Using the Descriptive Claims tool, add depicts statements to all the files in the Pagepile.
This solution is quite time-consuming, as it requires semi-manual work to create the Pagepiles, which is why we did not follow this way.
The major outcome of this project was learning about the possibilities and limitations of the available tools from the perspective of a medium-scale GLAM upload. Regrettably, our selection of SDC statements was determined by the technical solutions available. We felt limited by the tools and unable to use the full potential of the data shared by the GLAM. While a lot can be done already, thanks to the contributions of volunteer tool developers, the lack of fully automatic solutions, integrated with the existing upload software, is palpable.
Future[edit]
Following the development of Structured Data on Commons has been very interesting from the point of view of GLAM uploads. SDC has an enormous potential to make Wikimedia Commons more understandable and manageable for GLAM staff who might feel overwhelmed by the complex wikitext descriptions with their dozens of templates and the category system that has evolved organically over the years. GLAM staff are usually expert users of databases and catalogs, used to well-thought-out categorizing systems. They expect to be able to query the collections using different criteria, which is not easy today. If all files had structured data statements, making even extremely fine-tuned queries would be trivial (e.g. all paintings by female European artists depicting cats created in the 19th century).
However, in order to actually achieve this dream – providing detailed structured data for the backlog of millions of files that are already up on Wikimedia Commons, as well as making it easy to include in new uploads, especially large-scale ones – the development of efficient and robust tools is crucial. This is not something that can be left to volunteer developers. Ideally, SDC support should be implemented in any of the tools that are currently used by Wikimedians, of which OpenRefine and Pattypan are obvious candidates, due to their popularity among Wikimedia Commons uploaders.
Indeed, the developers of OpenRefine are aware of how important implementing SDC support in their application would be for the Wikimedia community.[9] This is a very realistic goal, seeing that OpenRefine already supports Wikidata reconciliation and is thus a popular tool among Wikidata editors. Both Wikidata and SDC use Wikibase as their underlying platform; extending the Wikidata support in OpenRefine to any Wikibase instance would open up possibilities including, but not limited to SDC.[10]
References[edit]
- ↑ Help:Wikitext
- ↑ Help:Gadget-ACDC
- ↑ https://tools.wmflabs.org/pagepile
- ↑ https://petscan.wmflabs.org/
- ↑ User:Magnus_Manske/sdc_tool.js
- ↑ Category:Media_contributed_by_Tekniska_museet:_2020-02
- ↑ https://w.wiki/JEf
- ↑ https://phabricator.wikimedia.org/T231979
- ↑ https://github.com/OpenRefine/OpenRefine/issues/2144
- ↑ https://github.com/OpenRefine/OpenRefine/issues/1640