
FindingGLAMs/White Paper/EMPOWER
A White Paper as Guidance for Future Work
developed as part of the FindingGLAMs project
Case Study 5: EMPOWER – Engaging Museums around Problematic data On Wikimedia’s Educational Resources[edit]
-
 Participants in the problematic data workshop.
Participants in the problematic data workshop.

Key facts[edit]
Time: 1 December 2018 – 30 September 2019
Organizations involved: Swedish National Heritage Board, Rijksmuseum, The National Library of Sweden, Swedish National Archives, National Museum of Science and Technology, Nobel Prize Museum, National Museums of World Culture
Wikimedia/free knowledge communities involved: Wikimedia Sverige, Wikimedia Finland, Wikimedia Foundation
Keywords: Problematic data, outdated terminology, bias, Wikimedia Commons, Wikidata
Key conclusions[edit]
- Handling problematic data is an ongoing process and historic data and information should not be deleted, but instead updated and supplemented.
- In cases where we add new data and information we should use tools that support transparency in order to increase knowledge.
- We should ensure traceability in the process by presenting all the arguments on why new data and information needs to be added.
- There is a shared ownership of open platforms that makes collaborative learning and collaboration possible.
- Open platforms create opportunities for targeted interventions by affected groups, e.g. by adding information in their own languages.
Background[edit]
Collections at GLAM institutions have been built up over a long period of time and the documentation describing the content is often a reflection of different time periods and their values. The collections' information and data can be regarded as time capsules from the past with descriptions that can nowadays be regarded as unexplained, unclear and problematic. This applies not only to Sweden, but is generally applicable to all countries where collections are being built up over long periods of time.
The discussion of sensitive material in the collections is a recurring topic in the GLAM sector. There is a lot of documentation of issues through previous seminars and work. The focus has however largely been on interpretation and management within each GLAM institution’s own collection. Open platforms and free licenses mean new problems to be solved. One advantage of using structured data is that you can make better and deeper searches. Open data can also mean that others can do searches from outside of your web pages if you transfer information from a text into accessible structured data.
The book Words Matter by The National Museum of World Cultures in the Netherlands is a research publication on potentially sensitive words in the museum sector.[1] Words Matter contains a review of some 50 problematic words and concepts, with suggestions of words to use in their place. These issues had a major impact in the media when the Terminology group at the Rijksmuseum worked with a selection of titles on works of art in the collection.[2][3]
There is an increasing debate within the museum community about the morals and ethics, if not legality, of museums creating and copyrighting media based on unethically acquired objects.[4] On the Wikimedia platforms, material may not carry any restrictions beyond those of CC BY-SA on Wikimedia Commons[5][6] or CC0 on Wikidata.[7]
Questions before uploading data to open platforms[edit]
- What are the benefits to the GLAM institutions of making problematic materials available?
- How can we reduce the concerns that exist when handling problematic material?
- How can we get GLAM institutions to make more problematic material available?
Questions after the upload[edit]
- How can we create value for, and give ownership to the group that has been exposed?
- What are the needs of processes, guidelines and tools when publishing on open platforms?
- How can the community of the platform aid in updating and contextualising the problematic data?
Follow-up activities[edit]
- How to follow up and maintain published material?
- How can you ensure that the material is reused, linked and disseminated in a way aligned with the intentions for making it available?
Implementation[edit]
We have used an explorative investigative method and contacted organizations that have worked with sensitive data and information. There were 24 participants in the workshop from institutions representing libraries, archives and museums.[8] The selection was made through invitations to Swedish institutions that have had some previous experience of working on open platforms, or have been in contact with Wikimedia Sweden in other projects, and to a selected few international organizations. The workshop was held at Goto 10 in Stockholm, the coworking space where Wikimedia Sverige’s office is located.
Communication[edit]
The communication has been based on contacts and inquiries with previous partners before the workshop which was conducted on 30 August 2019. In this way, the research work was combined with a discussion of how methods and tools can be developed on open platforms.
We wrote two blog posts, Workshop on problematic data?[9] and – Börja bara! Börja med det värsta ni har![10] (Just start! Start with the worst you have!), on Wikimedia Sverige’s website. The first post was an invitation to the workshop and was shared in social media by both Wikimedia Sverige, our partner the Swedish National Heritage Board, and by Digisam, the national coordinator of digitisation. The blog post about the Problematic Data workshop was also included in the September newsletter from Wikimedia Sverige.
On the 16th August the project was presented at the Wikimania conference in Stockholm in the GLAM space section Structured Data on Wikimedia Commons for GLAM-Wiki.[11]
Presentations[edit]
From a larger selection, we invited three lecturers with experience in dealing with problematic data, both in previous work and in current projects. The lecturers oepened the workshop on August 30 with presentations on how they and their organizations work with problematic data. The purpose of the presentations was to give all participants an understanding of how problematic data can look and be handled at different institutions for the workshop part of the day. The recorded presentations and slides from the workshop are available on Wikimedia Commons.[12]
Rijksmuseum’s terminology project[edit]
Bas Nederveen, an information specialist at the Rijksmuseum, has worked from the start in a special group that has been tasked with critically assessing previously used terminology, and describes this in the lecture "Today's language for today's audience".[13] Problematic terms can be of the following nature:
-
 Terms. An image from Bas Nederveen's lecture on terms and terminology.
Terms. An image from Bas Nederveen's lecture on terms and terminology.

The process starts with choosing the term you want to work with. Terms mainly come from our collection database but may come from another work at the museum, such as a work in progress with a book or an exhibition. In working with terms, you research and consult experts in the subject, both internally with the curatorial staff at the museum and externally with the groups. Based on this research you choose an alternative. New titles and descriptions are added to the collection database. As of that moment, these become the preferred titles and descriptions when searching the database and the website. All research is documented in an information sheet with a description of the problem, the solutions and which sources were consulted.
Difficult person museum[edit]
-
 From the presentation by Stefan Bohman.
From the presentation by Stefan Bohman.

Stefan Bohman is a former chairman of Swedish ICOM and has written the book Skelett i garderoben (Skeletons in the closet) about persons that are popular for some reason, but also have a problematic history and how this is presented in the person’s museum.[14] In the lecture at the workshop Stefan describes some conclusions on how difficult person museums[15] work on problematic issues.
There are two main issues to be considered:
- Who has the right to decide what to be remembered or forgotten from the past?
- What stories are told and what stories are not told?
These issues will also become relevant when choosing what to upload to open platforms, and what to withhold. Stefan Bohman presents[16] several strategies for how GLAM institutions deal with difficult questions:
- Full account: The museum tells the visitors about the difficult questions in exhibitions and other material.
- Omitting: The problematic fact is not included in the museum's exhibitions or in any other museum material.
- Double bookkeeping: The museum presents the difficulties in different ways – one for the ordinary public and one for those with a special interest.
- Minimizing: The problematic facts are presented, but in a minimized way.
- Reduction of responsibility: The museum claims that everyone did the same, the society during the time “was just like that”.
- Comparison: The person did really do bad things – but in comparison to their contribution to society it’s of lesser importance.
- Change of subject: The museum concentrates on other subjects than the person’s history and work.
WikiProject Saami[edit]
Susanna Ånäs is project coordinator at Wikimedia Finland and a project leader for the WikiProject Saami.[17] The project examines and improves knowledge about the Saami representation on Wikimedia platforms.
-
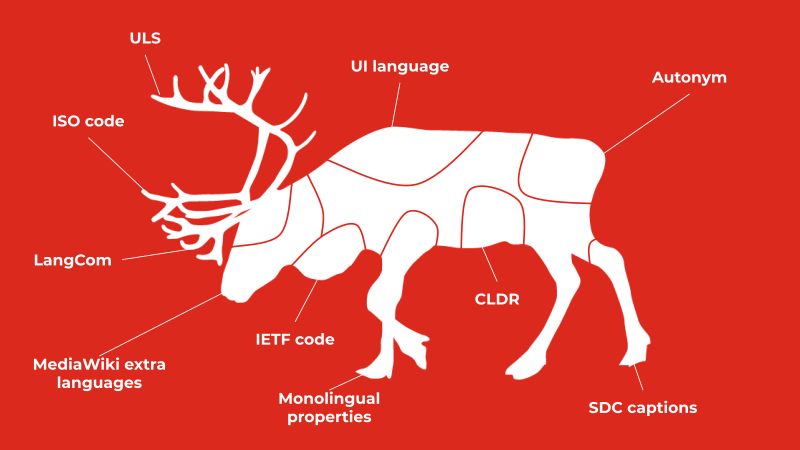 One solution does not work for every Wikimedia project.
One solution does not work for every Wikimedia project.

The vision is to “make the Wikimedia projects more useful to the Saami communities, help the communities control the circulation of the representation of their culture, and to make the Saami communities, languages, and cultures more visible and factual across all Wikimedia projects.” Susanna highlights several areas where work can be done to support this vision.[18]
- Aspects of protection: Attention to copyright, privacy and personality rights. Culturally sensitive and sacred knowledge. Protection against commercialization, theft and vandalism.
- Visibility of sensitive data: Is there a need to exclude information from Wikimedia projects? Ways to describe and filter from display? Remove location data?
- Ways to correct information: Remove or tag fake indigenous content. Add and use indigenous names and nationalities. Identify and tag personalities and locations when appropriate. Express consent and restrictions. Add knowledge and data provenance.
- Decolonising the digital commons and terminology: Translating and importing concepts into Wikidata enables tagging in minority languages. Initiative to import a multilingual Saami museum thesaurus and Saami place names. Propose the use of Traditional Knowledge labels for Saami communities.
- Consent requires documentation and infrastructure: Wikimedia environment has opportunities to store consent. OTRS is used for licensing purposes, and can be repurposed for consent.[19] In events it is possible to ask for consent. Children cannot legally consent. Both opt-in and opt-out should be possible, and the right to be forgotten should be respected.[20]
Workshop[edit]
In the introduction to the workshop, a brief presentation of Structured data on Commons[21] and a couple of different variations on templates that are already used on Wikimedia Commons was made. Templates can be seen as alerts and extra customized additional information. The purpose was to show the tools that exist and to keep in mind the platforms where development can take place.
The workshop was based on the open space method[22] which takes advantage of the participants' experience and ability to create relevant questions. What was generally desired for future work on problematic data was better discussions, more experiences, good examples, advice and support, more knowledge, how to give back to minorities, strategies and more confidence in what is problematic.
The starting point and the initial question was: What problematic situations have you encountered or heard about when materials were made available to a larger public? The participants in the workshop came from several different institutions, for example the Swedish National Heritage Board, Rijksmuseum, The National Library of Sweden, Swedish National Archives, National Museum of Science and Technology, Nobel Prize Museum, National Museums of World Culture.
This question and subsequent questions generated 18 proposals in areas for further discussion divided into two sessions during the afternoon. The person who suggested a problem area was also given the task of documenting the discussion in a report template. Out of the 18 proposals for in-depth discussion, the result was 10 reports that became working material for further analysis. Some examples of focus areas from the group discussions:
- Trigger warnings: Problematic expressions and outdated words.
- Medical images: Old language and abusive material.
- Reproduction of old values: When there are no valid facts.
- Lack of interest from colleagues: How we talk about and describe minorities.
- Relatives: Relatives or groups that do not like the museum's story.
- Unconscientious pictures: Children, bodies, minorities, tortured and dead people.
- Illegal activities: Legal considerations.
Outcome[edit]
Thorough preparatory work should be done before GLAM institutions can share problematic data with free licenses on open platforms. The conclusions after the lectures and workshop is that you should not change historical descriptions and, if necessary, expand and add new updated information. In this way, you maintain provenance and traceability over time. The reports were analysed and grouped around five general issues, presented below.
Ethical perspectives[edit]
Ethical perspectives seek to resolve questions of human morality by defining concepts. There is data where the initial creator might not have asked for the consent of those depicted, or where they lacked the de-facto ability to refuse consent due to asymmetric power relations. There are photographs of dead children and adults, tortured people, and minorities who do not want to be depicted after death in an online collection. This may not always be a legal issue, but an ethical one. There are already ethical guidelines for many cultural institutions, but those need to be further clarified when it comes to uploading materials to open platforms.
Legal aspects[edit]
There may be legal aspects of sharing problematic data and files on open platforms. The laws for abusive and racist material may look different in different countries. When is consent needed and how can it be expressed effectively? These issues are often difficult and have to be solved on a case by case basis. There are risks for institutions to end up in a context that cannot be influenced by themselves. There is also a fear that images can be used and edited by others and where the institution can become indirectly responsible. The intention when making problematic material available is to have transparency and clarity.
Terminology[edit]
Terminology serves to facilitate communication between people who are familiar with a subject area. Certain words and phrases used in the past may be perceived as offensive, unintentional or not, to a more contemporary audience and there is no reason to perpetuate racism or sexism. There are several different glossaries but they are not jointly created. Translation is an important issue when the terminology is specialised and concepts do not overlap perfectly in different languages. Working together with terminology on open platforms let institutions mix and influence the interpretation and the shared meaning of words and how they are used.
Labels[edit]
Problematic and sensitive material is often about people, specifically from disenfranchised communities. What is the significance of the description of these communities when made by an outside party, and how can this change over time? How do we name groups and what happens when we use outdated concepts or names? There are problems with power and interpretability that are manifested throughout the communication of society.
Label systems can be seen as a method for tagging different kinds of problematic material. The project Traditional Knowledge Labels[23] is an example of such a system. To add information from a label system can provide guidance in the reuse and access to culturally sensitive content. A conceptual system could be used by indigenous communities to add protocols for access and use of cultural heritage but this must be investigated further.
Labels can be seen as a basis for further discussion. Responsiveness and cooperation are two keywords in the work to agree on commonly agreed descriptions. Tools that support different languages are critical to success here.
Reuse[edit]
The point of knowledge on open platforms is reuse and it’s part of the concept of open[24] that people can edit and improve the content. This can be extra sensitive when it comes to problematic data. High-resolution digital images of materials can be reused in commercial contexts, which can be perceived as tasteless, ignorant, and/or inaccurate. Image agencies can place their own restrictions on free material on open platforms, with uncertainty as a result.
The advantages of working with problematic data on open platforms is that it creates a transparency and visibility that shows that these problems are actively taken seriously. It may be better to be the one who devotes resources to this work at an early stage and shows possible solutions to difficult questions.
It is difficult to generalize problematic data as it deals with different types of problems and each case has to be dealt with separately. But open platforms nevertheless provide opportunities to make materials accessible and to be able to influence how the material is curated. Ownership and curation becomes a joint commitment and responsibility.
Two tools to reduce the negative impact of reuse are; increased public understanding of how freely licensed material can be reused, and that the context in which material is encountered does not necessarily reflect its origins. Increased awareness on the side of content providers about potential reuse, so as to be prepared in the case of unwanted reuse.
Future[edit]
The number of uploads will increase as more material is given free licenses. There will continue to be a need for advice and support as the background, material and process will be different in each upload. We see an opportunity to take advantage of all experiences by documenting good examples in the work of developing the management of sensitive material.
Documentation and processes to develop[edit]
Wikimedia has the capability to create a knowledge bank around problematic data. It can support collaboration between institutions working on transparent open methods and assist in disseminating results. We recommend further work, development and projects in the three areas described below. For a good result we suggest working with institutions that have unpublished collections that contain problematic data.
Ethical perspectives[edit]
Existing ethical guidelines should be updated to also include open platforms. This can help institutions when preparing a collection with problematic content or when looking at sharing content on open platforms for the first time. We can release a new code of ethics under a free license and focus on the part that affects publishing on open platforms. We can write and organize a code of ethics for open platforms with inspiration from four areas:
- Code of ethics for galleries.
- Code of ethics for libraries.[25]
- Code of ethics for archives.[26]
- Code of ethics for museums.[27]
Legal aspects[edit]
There are several different laws that are relevant when dealing with problematic data. There is a need for more legal knowledge in this area with an international perspective. It is also an area where changes are constantly taking place so continuous education and platforms where this knowledge is easy to update are desirable. This work should preferably be done by country but can be compared to each other in the form of a table.[28] Working in a project on an open platform (one that allows anyone to freely access, use, modify, and share the content for any purpose[29]) can be used for four areas of legal aspects.
- Harassment, discrimination and other abusive treatment.
- The law and rules of copyright.
- Integrity and general data protection regulation.
- Indigenous and minority rights.
Terminology[edit]
Defining problematic terminology and preferable alternatives to it is an important step in recognising and addressing problematic data. It is crucial to work on this together on open platforms so that more institutions can influence the interpretation and, by extension, the shared meaning of the terminology. When more actors join the chosen platform becomes an authority. It is important to work directly on open platforms with free licenses so that there are opportunities for several players to contribute. If the terminology is to be used and remain relevant, it must also be maintained and updated. We can work with the terminology directly on three global projects with support for hundreds of languages.
- Add words at Wiktionary[30]
- Add information at Lexicographical data[31]
- Add knowledge and sources on articles at Wikipedia
Wikimedia tools for development[edit]
There are specific tools and processes that can be developed to facilitate work in databases and on open platforms. This can be about using the tools in new processes or in new ways that are suitable for uploading and handling problematic data. Our proposal is to continue with processes and development around these three areas, each with an associated set of tools. Preferably with an unpublished collection that contains problematic data where the purpose is to release it on an open platform. The tools can be developed in different ways depending on the system and platform. On the Wikimedia platforms and projects, development takes place continuously with the aim of collaborating and benefiting from each other’s contributions and experiences.
Structured data[edit]
The technology Structured Data on Commons[32] aims to allow structured and machine-readable metadata to be associated with the free media files on Wikimedia Commons, to make them easier to view, search, edit, organize and re-use. This is one way in which data could be marked as potentially problematic using different statements and properties. The strength of Structured Data on Commons is that it is an open system, meaning anyone can add information. This opens up a discussion about individual interpretations that fit the character of problematic data very well. The result is a combination of domain knowledge of the content and how the technology supports the dissemination of this curated knowledge.
Structured Data on Commons is fairly new and more development is needed to make this mechanism easily usable for the case of problematic data.
Templates[edit]
One way to highlight important information can be to work with templates using visual elements, such as warning texts or other labels. This can be done easily in many systems and can be a way to make visible selected problematic parts at an early stage. These templates can be designed in different ways depending on the situation.
Templates on Wikimedia Commons[33] can also be further developed in both form and content. There are opportunities for specialized solutions based on presuppositions. These specialized solutions can be investigated and, above all, tested in real situations. There are ethical guidelines and laws in most areas and one way to add knowledge about problematic data is to actively link to them. Referring to a guideline or law can be a way to initiate a discussion about whether or not certain problematic data and images should be on free platforms. It is also a way to have contact with organizations that are a part of creating the practices in the area. A template can have one or more organizations as senders and refer to one or more relevant authorities in each case. We can also explore more about whether a labeling system as, for example, Traditional Knowledge Labels[34] work on open platforms.
It should be noted that templates, and metadata in general, often get divorced from media representations when these are published or reused on other platforms.
Properties[edit]
Properties[35] in Wikidata are a way to describe an item.[36] The use of properties can in a longer perspective become an important aspect in handling problematic data. Wikidata properties that describe terms as problematic might be used in a similar way to what dictionaries do. A description in dictionaries for certain words and concepts can for example be outdated when they want to show that the word is no longer in use. Properties for describing objects can be developed by addressing the need for similar solutions on open platforms. Developing new properties on Wikidata follows a process where several users can participate and in this way the property becomes embedded within the community even before it is used.
Having many properties that describe an object can be a way to increase the granularity of the information. Having the involved actors agree on terms and concepts makes it easier to collaborate. Along with reaching an agreement, you can also link to lexicons, sources, and discussions that describe more about the background of why the property is used for the problematic data.
References[edit]
- ↑ https://issuu.com/tropenmuseum/docs/wordsmatter_english
- ↑ https://www.rijksmuseum.nl/en/research/terminology
- ↑ https://hyperallergic.com/263180/why-the-rijksmuseum-is-removing-bigoted-terms-from-its-artworks-titles/
- ↑ https://copyrightcortex.org/
- ↑ Commons:Licensing or CC0 on Wikidata.
- ↑ Wikidata:Licensing
- ↑ Wikidata:Licensing
- ↑ https://se.wikimedia.org/wiki/Projekt:GLAM_2019/Global_Metrics#Problematisk_data,_Stockholm
- ↑ https://wikimedia.se/2019/07/31/hur-ska-vi-hantera-problematisk-data/#english
- ↑ https://wikimedia.se/2019/09/04/borja-bara-borja-med-det-varsta-ni-har/
- ↑ Structured_Data_on_Wikimedia_Commons_for_GLAM-Wiki
- ↑ Category:Problematic_Data_workshop_2019
- ↑ Problematic data - Bas Nederveen.webm
- ↑ http://libris.kb.se/bib/9kktljdz7lrnxz9p
- ↑ http://www.icom-helsingborg-2017.org/conference/blog/blog_home/difficult-person-museums
- ↑ File:Problematic_data_-_Stefan_Bohman.webm
- ↑ WikiProject Saami
- ↑ File:Problematic_data_-_Susanna_Ånäs.webm
- ↑ Commons:OTRS
- ↑ Right_to_be_forgotten
- ↑ Commons:Structured_data
- ↑ Open_Space_Technology
- ↑ http://localcontexts.org/tk-labels
- ↑ https://opendefinition.org/
- ↑ https://www.ifla.org/faife/professional-codes-of-ethics-for-librarians
- ↑ https://www.ica.org/en/ica-code-ethics
- ↑ https://icom.museum/en/activities/standards-guidelines/code-of-ethics/
- ↑ Example of comparative table Commons:Freedom_of_panorama
- ↑ https://opendefinition.org/
- ↑ https://sv.wiktionary.org/
- ↑ Lexicographical_data
- ↑ Commons:Structured_data
- ↑ Commons:Templates
- ↑ https://localcontexts.org/tk-labels/
- ↑ Wikidata:Property_proposal
- ↑ Wikidata:Glossary