
FindingGLAMs/White Paper/WORD
A White Paper as Guidance for Future Work
developed as part of the FindingGLAMs project
Case Study 3: WORD – Wikimedia Organizes lexical Resources Digitally[edit]
-
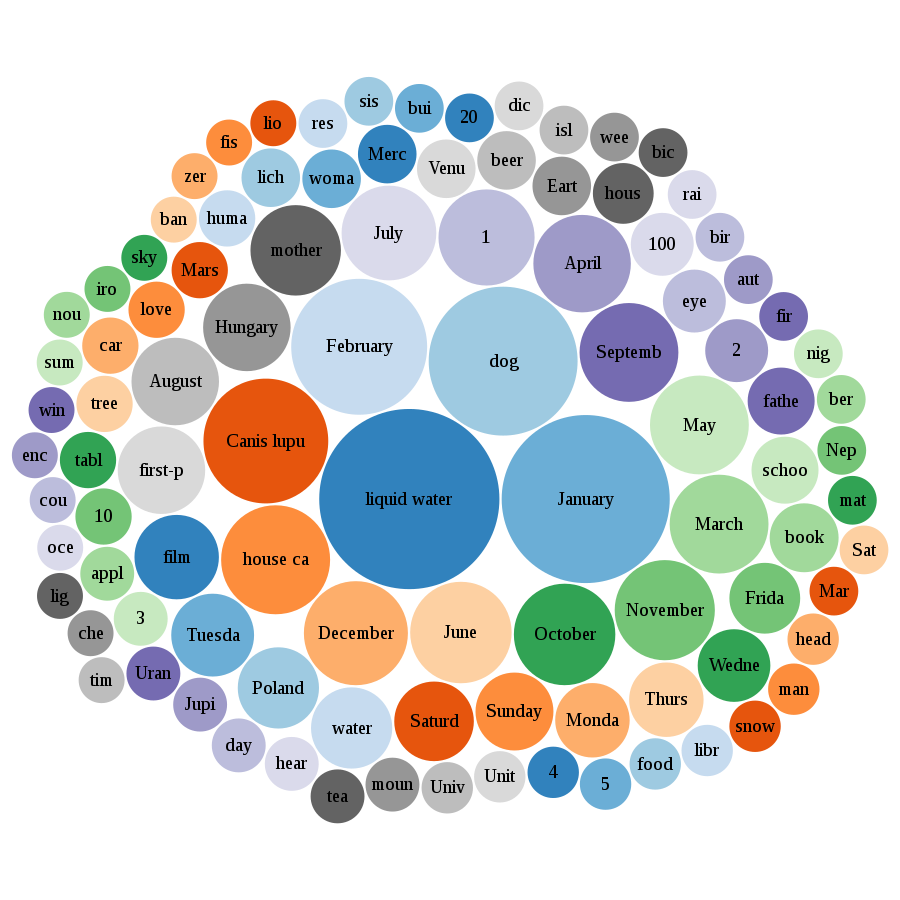 The 100 most translated concepts using lexemes in Wikidata (February 2020)
The 100 most translated concepts using lexemes in Wikidata (February 2020)

Key facts[edit]
Time: Spring 2019
Organizations involved: Swedish Institute for Language and Folklore, European Commission
Wikimedia/free knowledge communities involved: Wikimedia Sverige
Keywords: Wikidata, lexicographical data, Wiktionary
Key conclusions[edit]
- There is a burgeoning interest from partners in lexicographical data on Wikidata.
- Many lexicographical data editors use external tools developed by volunteers, the emergence of which is caused by the lack of efficiency of the native interface.
- The existing popular tools for large-scale editing lack support for lexicographical data, which makes it harder for experienced editors to apply their expertise.
- Synergies between Wiktionary and Wikidata are possible and would benefit the communities by using volunteer resources more efficiently, but require that the possibility of linking between lexemes and Wiktionary entries is implemented. However, the different licensing terms of the two platforms are an obstacle to data re-use.
- The potential of the lexicographical layer of Wikidata as a multilingual dictionary is severely underutilized due to the lack of agreement on how to link between equivalent lexemes in different languages. A more straightforward technical solution could make this more user-friendly.
- The value added from developing a multilingual thesaurus, glossary and dictionary for the GLAM sector has been highlighted by multiple actors. This needs further investigation for a fruitful implementation.
Background[edit]
The Swedish Institute for Language and Folklore (Institutet för språk och folkminnen) is a government agency that works with research and preservation of languages used in Sweden. In spring 2019, we had a number of meetings with them to investigate the possibilities of sharing one of their openly licensed lexicographic resources on the Wikimedia platforms. At that time, the lexicographical namespace on Wikidata had been available for about a year and had dozens of active users working on many languages. It was established enough for us to research its suitability for this task, but not as mature as at the time of writing (January 2020).
Staff from Wikimedia Sverige participated in a number of discussions and workshops organized by the European Commission around the next steps of financing the digitization of Europe's cultural heritage.[1] The value of creating dedicated language resources for the cultural heritage sector was frequently highlighted. The hope is that efforts in the area would support cross-European efforts to digitize materials. This is considered of high importance to the European Commission and many industry experts.
The material[edit]
Among other things, the Swedish Institute for Language and Folklore publishes material, such as glossaries, for translators and interpreters between Swedish and other languages.[2] Many of them are based on the so-called Basic glossary for interpreters (Basordlista för tolkar), a list of vocabulary in the fields of civics, medicine and law that the Institute considers essential for interpreters who assist clients in the Swedish public sector. This document, covering over 6,500 words and terms, has been released by the Institute under the CC0 license, and shared with Wikimedia Sverige.
Every entry in the document consists at least of the following:
- the lemma, e.g. ackordsättning,
- the definition in Swedish, e.g. fastställande av betalning i förhållande till mängden utfört arbete, and
- the domain tag, e.g. arbetsmarknad-och-pension, classifying the entry as belonging to the area “labor market and retirement”.
Some of the lemmas are proper names, e.g. of social institutions. Some of the entries contain additional information such as synonyms. The following thematic areas are covered: medicine and psychiatry (2,498 entries), law (1,535 entries), labor market and retirement (917 entries), social insurance (844 entries) and miscellaneous (622 entries).
Lexicographical data on Wikidata[edit]
Lexicographical data[3] was introduced to Wikidata in May 2018. Since then, over 234,000 lexemes have been created, representing 350 languages. 12 languages have over 1,000 lexemes each. The largest languages are Russian (101,000 lexemes), English (38,000 lexemes), Hebrew (28,000 lexemes), Basque (18,000 lexemes) and Swedish (11,000 lexemes). As a point of comparison, there are over 78,000,000 items in the main Wikidata namespace.
In February 2020, the English Wiktionary had 512,042 gloss entries (basic forms, i.e. not inflected forms; in Wiktionary, inflected forms can have their own pages) in English.[4] It usually is the Wiktionary in a particular language (i.e. not the English Wiktionary) that boasts the largest number of entries in that language; Russian Wiktionary has 432,650 Russian entries[5] and Swedish Wiktionary has 78,194 Swedish entries.[6] This gives an indication of how much work remains for Wikidata editors to at least match the quantity of data in Wiktionaries.

Lexemes are the basic unit of lexicographical data on Wikidata, akin to how items are the basic unit in the main namespace.[7] Each lexeme has a unique identifier starting with the letter L, to distinguish them from main namespace items, whose identifiers begin with the letter Q.
A lexeme contains at least the following information:
- Language, e.g. English
- Lexical category, e.g. verb
- Lemma, e.g. distinguish
This data is necessary to input to create a minimum viable lexeme item. A lexeme can also contain more detailed information, including but not limited to:
- Grammatical gender, e.g. neuter or common for Swedish; neuter, feminine or masculine for Bulgarian.
- Forms, e.g. achieve, achieves, achieved.
- A form can be tagged with its grammatical properties, e.g. achieves with simple present and third-person singular.
- A form can be accompanied by a link to a recorded pronunciation on Wikimedia Commons.
- Senses (definitions) – one or more.
- On the sense level, the lexeme can be linked to other lexemes, indicating semantic relationships, such as synonyms and antonyms.
- The style of the sense can be included, e.g. to indicate that ass is a pejorative synonym of buttocks.
- Usage examples.
- If the example comes from authentic material, such as a book or newspaper, it can – and should – be accompanied by a reference.
- If the lexeme has several senses, the usage example can be linked to one or several of them.
- The component stems of compound words can be indicated, e.g. foot and ball for football.
- Links to entries in external services, such as external databases and dictionaries, can be supplied. None have been implemented for Swedish so far, but links in other languages include DanNet 2.2 (P6140) and Uralonet (P5902).
A more detailed description of the data model can be found in the official documentation.[8]
Wikidata as a multilingual dictionary[edit]
Due to the international scope of Wikidata and its multilingual community, we find the potential to use the lexicographical namespace to build a translation dictionary very interesting. Wikidata – both the underlying software and the community – already has a heavy emphasis on internationality and multilinguality, as the labels and descriptions can be entered and displayed in any language.[9] This is one of the aspects of Wikidata that make it unique and powerful.
Translations constitute a major part of Wiktionary, but are not easy to handle for either editors or readers. Every language version of Wiktionary is independent, meaning that in order for a Swedish entry to include a translation to another language, the translation has to be added manually – even if the corresponding foreign language entry already contains a translation to Swedish. Such an edit in one language version of Wiktionary is not reflected in other language versions. New editors often find this architecture difficult to understand, as it requires duplication of work, putting a strain on limited volunteer resources.
Wikidata, with its centralized architecture, could be providing a solution to this problem. In practice, it does not do this in an efficient or user-friendly way. The lexeme namespace, which is under current development, at this stage does not yet seem to be designed with interlanguage links in mind. Most importantly, there is no standardized way to connect lexemes in different languages that share a meaning to each other. One way to do this is by using the property item for this sense (P5137) to link one lexeme’s sense to a corresponding Wikidata item. For example, the linguistic concept island is linked to the encyclopedic concept island. This makes it easy to link multiple lexemes in different languages to the same encyclopedic item, indicating they are all expressions of the same concept. However, it is a rather blunt tool, best suitable for concrete nouns, such as cat, knife or Sweden (of course, translators know that great care must be taken in assuming perfect one-to-one relationships even between such words). It is less good at expressing subtle stylistic or dialectal differences, and even worse if applied to non-concrete vocabulary such as adverbs or conjunctions. For example, in Swedish the words ja and jo can both be translated as yes, but are used in different grammatical contexts and express different levels of agreement; a simple one-to-one relationship fails to represent the difference between them and could be actively misleading the user.
Another useful property is translation (P5972), which is used to link to a “word in another language that corresponds exactly to this meaning of the lexeme”. This seems to be a fitting solution, but in practice it is not very useful. If the word in question has equivalents in 50 languages, then an editor would have to add all of them as values of this property. This is not practical or realistic; as a result, the property is used only 1,537 times – not a lot considering there are over 234,000 lexemes.
In conclusion, the available architectural solutions are unsatisfactory from the point of view of creating a multilingual dictionary, both for the editor and the reader and will need to be developed more to address these issues.
Problem[edit]
Our goal was to investigate the viability of including the monolingual lexicographical data provided by the Institute for Language and Folklore on Wikidata, with a long-term perspective of also including multilingual data in a structured way to provide maximum benefit for the users. An important aspect of the case study is comparing the lexicographical layer in Wikidata with another Wikimedia platform, Wiktionary, which has an established position as a free dictionary platform and is presumably more familiar to the general public.
The identification and connection between material in different institutions spread across the world is currently very hard, partly due to language barriers. The structured lexicographical layer has the potential to simplify the process, while also improving automatic translation tools etc.
Implementation[edit]
{
"uppslagsord": "arbetarskydd",
"definition": [
"verksamhet för att förhindra och begränsa olycksfall och yrkessjukdomar i arbetet"
],
"doman": "arbetsmarknad-och-pension"
},
{
"uppslagsord": "arbetsavtal",
"definition": [
"avtal om villkor för viss arbetsprestation gällande anställning el. uppdrag"
],
"doman": "arbetsmarknad-och-pension"
}
Example of the data structure in the data shared by the Swedish Institute for Language and Folklore.
Using this background, we examined the existing possibilities for working with the dataset provided by the Swedish Institute for Language and Folklore on Wikidata.
At the time we carried out the case study, the majority of the 6,000 terms in the glossary could not be found on Wikidata. Many of them are specialized terms, such as akrofobi (acrophobia) or etsskada (a type of tooth damage), a vocabulary class that the editor community might not have prioritized, instead focusing on building up the core, everyday vocabulary. The interpreter glossary could thus make a valuable contribution to Wikidata.
The glossary contains definitions of all the words, which raises its value for the project. Definitions are a neglected area on Wikidata, partially due to the previously mentioned copyright ambiguities of Wiktionary. In the absence of importable definitions, Wikidata editors have had to resort to writing their own, which takes time and requires lexicographical skills. Languages with comparatively few speakers and, consequently, few editors, such as Swedish, are at a disadvantage here.
The main challenge we encountered when working with the material provided by the Institute for Language and Folklore was that it lacked information about lexical categories. Those are necessary when creating lexemes on Wikidata; it is not technically possible to create a lexeme without including this information. Tagging the entries in the glossary with their lexical categories is a necessary prerequisite to importing it to Wikidata.
Some of the entries in the glossary are “phrases” in which a word is accompanied by its abbreviation, such as barnavårdscentral, BVC or svenska som andra språk, sva. Since a lemma can consist of several words and include punctuation (such as a phrase or a proverb), it is not possible to filter out this type of entries automatically. In this particular case, due to the small size of the dataset, it is possible to find them via manual examination and decide how to handle them on a case by case basis.
Outcome[edit]
Wikidata and Wiktionary[edit]
We found that the relationship between lexicographical data on Wikidata and Wiktionary, the free dictionary, is a topic of much discussion among the editor community. Wiktionary is an established platform with years of history. Many languages, including Swedish, have an active community which, despite not being as large as Wikipedia’s, have managed to build sizable and useful dictionaries. The Swedish Wiktionary contains over 77,000 entries in Swedish, as well as a large number of entries in other languages – mostly German, English, Finnish and French – with Swedish translations.
The main difference between Wikidata and Wiktionary is that Wikidata is a structured database, while Wiktionary stores all information about a word or a phrase in a single text field, not unlike a Wikipedia article. The structure of Wikidata enables analysis and complex searches, such as “find all Swedish verbs with usage examples sourced to books published in the 19th century” or “find all Swedish entries without a definition”. This is not possible in Wiktionary, at least not without downloading the contents and developing specialized analysis tools, something that in reality only researchers would be willing to do.
As a response to the “free” form of Wiktionary, its users have developed templates to display the content in a more structured and user-friendly way, akin to that of a commercial dictionary. Since all the content is free-text, editors are at a risk of making mistakes or accidentally violating community standards. It is important to note that since each Wiktionary is independent and governed by its community, the templates, guidelines and written and unwritten rules are different in each language version; an experienced Swedish Wiktionarian will face a considerable learning threshold trying to get involved in the English or German Wiktionary.
While data from the main Wikidata namespace can be displayed on Wikipedia, such a connection does not exist between the lexicographical namespace and Wiktionary. The potential for synergies between the two projects has been discussed by both communities, so it is not unrealistic to expect that such links will be enabled in the future. Information about the current technical situation regarding linking between the project can be found on the following pages: https://www.wikidata.org/wiki/Wikidata:Wiktionary and https://www.wikidata.org/wiki/Wikidata:Lexicographical_data/FAQ.
It is crucial to note that, for copyright reasons, it is not possible to import all the content of a language version of Wiktionary to Wikidata. Wiktionary is licensed under Creative Commons Attribution-ShareAlike (just like Wikipedia), a license not compatible with the CC0 license on Wikidata. The Wikimedia Foundation has published a preliminary perspective on the legal aspects of copyright for lexicographical data, with a US focus, concluding that definitions are creative enough to be copyrighted.[10] The resources that Wiktionary editors have spent years creating and thus of limited use for Wikidata editors.
Lexicographical infrastructure on Wikidata[edit]
The infrastructure for lexicographical data on Wikidata is not as mature as that for regular data. Because of that, some of the processes are not intuitive or comfortable.
One of the most tangible shortcomings is that searching for lexemes with the Wikidata search engine is not user-friendly. Firstly, it requires one to input a prefix to include the lexeme namespace, making it non-transparent to new users; secondly, it does not support filtering the results by language or part of speech, features one might expect from full-fledged dictionary software.
As a consequence, most of the active editors in the lexicographical namespace were established Wikidata editors before they started editing lexemes. They were already familiar with the platform and knew how to search for documentation. Many have been tracking the implementation and development of lexicographical data from the beginning. The learning curve for new editors without a background in Wikidata is steep, even if they have a background in linguistics or lexicography. Creating new lexemes using the native Wikidata interface is slow and requires a certain level of knowledge.
Because of these shortcomings the Wikidata community has developed a number of own tools for viewing and editing lexemes, e.g. Wikidata Lexeme Forms,[11] which enables users to quickly input several forms of a lexeme in pre-defined languages, without having to add the form tags by hand, like in the native editor.
Another area where the available tools are not satisfactory are large-scale automatic uploads. There are several toolkits for editing outside of Wikidata’s interface and uploading data to the main namespace, which are used by both volunteers and organizations, including Wikimedia Sverige. These include Pywikibot[12] (a Python library for interacting with the Wikimedia projects), OpenRefine[13] (an application for cleaning, enriching and reconciling data) and QuickStatements[14] (a web-based tool to edit large numbers of Wikidata items in a batch). None of these tools, which are well established among main namespace editors, support lexicographical data. As a result, the many proficient users of these tools cannot apply their skills and experience to the lexicographical namespace.
Some users have developed their own tools to automate performing specific tasks on a large scale. These include LexData[15] and Lexicator,[16] both developed in Python and available as open source. LexData is a small, language-independent framework designed to serve as a flexible base for scripts for editing lexemes. Lexicator is a tool to process grammatical data from – currently only Russian – Wiktionary and upload it to Wikidata.
The tools described above were created in order to do large scale mass uploads of lexicographical data. LexData is a generalized version of AitalvivemBot, built to work with French and Occitan lexemes from the Lo Congres database.[17][18][19] Lexicator was developed to import lexemes and their forms from Russian Wiktionary to Wikidata. Because of this upload, in November 2019 Russian was the largest language in the lexicographical namespace. The upload led to a discussion among the Wikidata community about how the previously described licensing differences between Wiktionary and Wikidata should be interpreted.[20] The conclusion was while the content of Wiktionary was nominally licensed CC BY, simple information, such as the individual lemmas and their forms, was so uncreative as to not being copyrightable in the first place, and thus should be possible to copy to Wikidata. The definitions, on the other hand, written by Wiktionary editors, do meet the threshold of originality and thus cannot be copied en masse into Wikidata without breaking the license terms. This is the same interpretation that the Wikimedia Foundation has reached.[21]
Future[edit]
Despite the fact that the Basic glossary for interpreters is in Swedish only, it is still very interesting to look at from the perspective of a multilingual dictionary. As mentioned previously, the Institute for Language and Folklore uses it as a base for their translation resources between Swedish and other languages. If those resources were released under an open license, it would give us an opportunity to do practical work with multilingual translation on Wikidata. That was a major motivation for us to examine Wikidata’s lexicographical namespace from a multilingual perspective.
Our conclusion in this area is that there are no standards or best practices when it comes to linking between lexemes in different languages. To a considerable degree, this might be caused by insufficient technical infrastructure; as there is no obvious way to do this task, editors have had to discuss and develop their own solutions. This causes problems for anyone who wishes to query and re-use the multilingual data, e.g. researchers examining the relationships between lexemes in different languages. It also raises the barrier of entry for new editors, increasing the risk of them becoming frustrated with the experience and not being as active as they would like – a significant problem for the young lexicographical data community.
Editors should be able to link between equivalent lexemes in different languages in an easy and straightforward way. An inexperienced user might think that translation property is the right tool to use for this purpose, but they are not aware that they have to manually add it to all equivalent lexemes in other languages – including the lexeme referred to as the translation. This task could be done automatically.
The technical possibilities of large-scale editing are also something that should be actively developed. Right now, there are several options, with different scopes and capabilities. What they have in common is that they are developed independently by volunteers to fulfill their specific goals and interests. While those tools might be very good at performing their tasks, it does not change the fact that the lexicographical namespace does not have an equivalent of the powerful tools used by main namespace editors, such as QuickStatements, OpenRefine or Pywikibot. This widens the gap between the lexicographical namespace and the rest of Wikidata, making it harder for experienced Wikidata editors to apply their skills to lexicographical data. This gap could be eliminated by either implementing lexeme support in any of the mainstream tools – OpenRefine is a good candidate, as it is a robust, flexible and popular application used by both Wikidata editors and other data specialists – or developing a specialized tool that is similarly flexible and user-friendly, not requiring programming knowledge and well-documented so that the barrier of entry can be lowered and non-Wikidata editors with an interest in lexicography can join the project.
The lexicographical namespace of Wikidata is young and under development. While the Wikidata community has done a tremendous job creating the content from scratch, we believe that systematic, large-scale uploads of existing data, as well as collaboration with domain expert partners, are the key to making lexicographical data on Wikidata as exhaustive and relevant as the main namespace. By basing our examination on authentic material, we brought into the spotlight those aspects of Wikidata’s lexicographical namespace that are important from the point of view of partnerships and large scale uploads.
To develop dedicated language resources for the cultural heritage sector is likely to receive funding from the European Commission in the coming years. Wikidata has the potential to be a very suitable platform to combine these resources if it receives some further development.
References[edit]
- ↑ https://ec.europa.eu/digital-single-market/en/digital-cultural-heritage
- ↑ https://www.isof.se/om-oss/publikationer.html
- ↑ Wikidata:Lexicographical_data
- ↑ Wiktionary:Statistics
- ↑ Викисловарь:Статистика
- ↑ Wiktionary:Om/Statistik
- ↑ Wikidata:Glossary
- ↑ Wikidata:Lexicographical_data/Documentation
- ↑ Help:Multilingual
- ↑ Wikilegal/Lexicographical Data
- ↑ Wikidata:Wikidata_Lexeme_Forms
- ↑ Manual:Pywikibot
- ↑ http://openrefine.org/
- ↑ Help:QuickStatements
- ↑ https://nudin.github.io/LexData/
- ↑ https://github.com/nyurik/lexicator
- ↑ https://github.com/aitalvivem/
- ↑ Wikidata:Requests for permissions/Bot/AitalvivemBot
- ↑ https://locongres.org/
- ↑ Reminder: your input needed about integration of Lexemes in Wiktionaries
- ↑ Wikilegal/Lexicographical Data