
Talk:CopyPatrol/Archives/2016
 | This is an archive of past discussions. Do not edit the contents of this page. If you wish to start a new discussion or revive an old one, please do so on the current talk page. |
Tool Labs vs on-wiki
(Discussion moved from Community Tech/Improve the plagiarism detection bot/Notes)
- Question as we start thinking about moving to Tool Labs: is it possible/desireable to port the old untriaged entries?
- User:Diannaa would be best to answer that. Doc James (talk · contribs · email) 12:26, 9 April 2016 (UTC)
- I'm not sure why you want to migrate the tool to Labs. Would that mean the results page currently located at User:EranBot/Copyright/rc would be moved to Labs? That has several disadvantages. (1) Navigation pop-ups would no longer be available to help quickly navigate to article history, preview the diff, or hover over the editor's name to get and idea who posted the edit; (2) links that I have already visited would no longer appear in a different color, which I currently use to alert me to whether I have visited a page before. This lets me know that I have likely already given the user a warning and that it's a repeat violator; and (3) if the page is on Labs, people are even less likely to visit it and help than they are right now. It seems to me that the main problem right now is attracting more people to help with the work. I'm the only one actively working on it right now. Diannaa (talk) 07:11, 10 April 2016 (UTC)
- While we have moved the database to labs I think, are we talking about moving the interface their aswell? I agree it is better to have the interface on WP as that is what people follow up are more used to. Doc James (talk · contribs · email) 09:05, 10 April 2016 (UTC)
- Maybe I misunderstood.In that case, I don't understand the question about porting the old untriaged entries. Diannaa (talk) 14:47, 10 April 2016 (UTC)
- Diannaa: I posted a new draft of the ideas on the project page. I didn't realize that you were the main user of the tool right now -- I should have been checking out the history on the checked pages, rather than the current page. :) I totally agree that the main problem is getting more people to help. I think the current interface is hard for people to learn and use, and I think there's a lot we can do to make it easier -- for you, and new people.
- We are thinking about moving the interface from on-wiki to Tool Labs -- there's a list of pros and cons on the project page. Of the three disadvantages that you listed, I think #1 (the nav pop-ups) is all stuff that could actually be built into the interface. For #2 (purple links that show you've seen the page) -- maybe we could figure out a way to give you that info in the interface as well. I don't have a brilliant idea for it at the moment, but let's talk about it. :)
- For #3 (people will be less likely to use it) -- I know there may be a barrier for people who don't want to follow a link off-wiki. I think that the features we can build on Tool Labs could make up for that, but I'd like to know what you think. -- DannyH (WMF) (talk) 23:06, 11 April 2016 (UTC)
- One of the long term hopes was to have "boxes" of content within each WikiProject page. The hope was to have the database stored at labs and than theses boxes on the WikiProject pages pull from that database. Is that possible to have multiple interfaces based on a single database that feed back answers to the database?
- The underlying reason for this proposal was the hope that it would pull in more volunteers which is one of the keys for the success of this tool. Doc James (talk · contribs · email) 05:21, 12 April 2016 (UTC)
- What we need to do is think about what kind of users we want to attract to help out with this work. There’s actually two aspects: removal of copyright violations from the encyclopedia, and educating and/or removing from the site users who are adding copyright material. Improving the appeal of the interface so that it resembles a game might attract the younger user, but is that the kind of person that will follow through and perform the educational tasks? My feeling is that the best type of person to take on this work is not a young editor who will play the interface as though it were a game, but rather adults, preferably administrators, who are prepared to follow up with repeat violators, issue warnings (even if the content has already been removed) and/or blocks, discuss issues, provide information about how to obtain an OTRS ticket, and perform revision deletions of copyvio diffs. The WP:CCI page is so backlogged, I am the sole person who works on it on most days, which makes it kinda pointless to open any more new cases. A primary benefit of the tool is that we will be able to detect and stop repeat copyright violators much more quickly than we have in the past, reducing the need to add further listings at WP:CCI. This benefit could be lost if the diffs are being assessed primarily by users who are not prepared to follow through and ensure the problematic users stop adding copyright violations.
How to use the information provided on the page can be problematic. It’s not always obvious what the actual source of the prose was. Sometimes it was copied from an old revision of the same Wikipedia article, or from a different Wikipedia article. Hits that show the Gale or self.gutenberg.org websites are almost always unattributed copying from within Wikipedia. For Gale, when clicking on the link to Earwig’s tool, it shows the source web page does not exist. Users who attempt to determine what’s going on without knowing this fact will likely incorrectly write off the event as a false positive. Cite DOIs will show up as a false negative of checking the Earwig tool, but Ithenticate shows the actual violation, as it is able to get behind the paywall and do a comparison with the actual paper rather than the abstract. Normally I open the diff, the history of the article, the Ithenticate link, and at least one of the Earwig links to determine what is going on. It’s still not always obvious what the original source was or whether or not a copyright violation has occurred. Steps involved: open the links, assess, remove the copyvio, check the article history for additional copyvio by the same editor, revision deletion, warn the user or block if they've already had warnings and are persisting with violations. Some I add to my list of editors for daily monitoring of contribs. I often check the user's other contribs for copyvio edits on other articles. That's all I've got for now. Hope this helps. Diannaa (talk) 22:16, 12 April 2016 (UTC)
- Maybe I misunderstood.In that case, I don't understand the question about porting the old untriaged entries. Diannaa (talk) 14:47, 10 April 2016 (UTC)
- While we have moved the database to labs I think, are we talking about moving the interface their aswell? I agree it is better to have the interface on WP as that is what people follow up are more used to. Doc James (talk · contribs · email) 09:05, 10 April 2016 (UTC)
- I'm not sure why you want to migrate the tool to Labs. Would that mean the results page currently located at User:EranBot/Copyright/rc would be moved to Labs? That has several disadvantages. (1) Navigation pop-ups would no longer be available to help quickly navigate to article history, preview the diff, or hover over the editor's name to get and idea who posted the edit; (2) links that I have already visited would no longer appear in a different color, which I currently use to alert me to whether I have visited a page before. This lets me know that I have likely already given the user a warning and that it's a repeat violator; and (3) if the page is on Labs, people are even less likely to visit it and help than they are right now. It seems to me that the main problem right now is attracting more people to help with the work. I'm the only one actively working on it right now. Diannaa (talk) 07:11, 10 April 2016 (UTC)
- User:Diannaa would be best to answer that. Doc James (talk · contribs · email) 12:26, 9 April 2016 (UTC)
- Yeah, this helps a lot. I agree that this is serious, painstaking work, and we need strong and competent people working on this tool. I'm not really thinking of this as a game, more a way of making this process accessible and usable by more people. I've only been using this tool occasionally over the last week or so, and I've seen a few really tough cases where I had to open every possible link and try to figure out what's going on.
- I think there's two branches of the project. The first is just to make the core functionality easier for users to understand and use -- exposing the WikiProject list, surfacing the helpful links that you're using nav popups to access. Just at the most basic level, Earwig's tool needs independent scroll bars so you can look at side-by-side comparisons. In my opinion, that's the single most aggravating part of assessing these, the thing that discourages me from using this tool more.
- The second branch of the project is to help you (and all the other users) organize the tools you need to do that deeper assessment. It'll still involve opening a lot of tabs, but at least we could put the corresponding links in the same place, so you're not clicking four random places in the box to get what you need. And then we can do things like building prompts for leaving a message on the editor's talk page, or helping you create a list of problem contributors that you're following. So it's really helpful to talk to you -- I want to keep talking about this, and drill into the needs in more detail. -- DannyH (WMF) (talk) 23:38, 12 April 2016 (UTC)
Draft wireframes
We've started putting a Copy Patrol prototype tool together, and below are some new wireframes. (We're making changes on both and figuring things out as we go, so don't expect the wireframes and the prototype to match right now.)
Ping for Diannaa, Eran and Doc James: what do you think so far? I'm sure there's something crucial that we've overlooked; there usually is. -- DannyH (WMF) (talk) 00:37, 5 May 2016 (UTC)
-
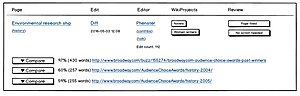 Item structure for Copy Patrol listings
Item structure for Copy Patrol listings -
 Opening the Compare pane, to compare the article and source
Opening the Compare pane, to compare the article and source -
 Selecting "Page fixed", the other button is grayed out
Selecting "Page fixed", the other button is grayed out -
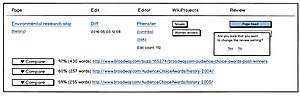 If you want to change the review setting, click on it again, get a confirmation box
If you want to change the review setting, click on it again, get a confirmation box -
 Filters for the Copy Patrol page, with WikiProject autocomplete
Filters for the Copy Patrol page, with WikiProject autocomplete -
 Filters, with WikiProjects selected
Filters, with WikiProjects selected






- The wireframes (and the WIP prototype) seems to be nice. eranroz (talk) 04:49, 5 May 2016 (UTC)
- When one clicks "page fixed", I do not think a confirmation step is desired as this slows down the review process. Doc James (talk · contribs · email) 07:12, 5 May 2016 (UTC)
- Oh, I should have described that better. Clicking the review setting is just one-click. The confirmation box is just if you want to change or cancel the review that you chose. I'm glad this looks good to you so far. -- DannyH (WMF) (talk) 16:22, 5 May 2016 (UTC)
- I don't see any issues with what you've got set up so far. Of course I would have to test it out to know for sure. Diannaa (talk) 20:49, 7 May 2016 (UTC)
- The test page http://tools.wmflabs.org/plagiabot/ is glitchy and incomplete (for example, it's important to have the full timestamp to assist in finding the correct diff on a busy page) but it looks like the work-flow will be similar to what I am doing now. Diannaa (talk) 21:02, 7 May 2016 (UTC)
- Not having to open (and later close) an edit window to mark a case as complete will speed up the work some. Diannaa (talk) 21:09, 7 May 2016 (UTC)
- @Diannaa: Could you explain a little more on what you mean by not having to open an edit window? What kind of workflow are you imagining? Thanks. -- NKohli (WMF) (talk) 14:11, 13 May 2016 (UTC)
- Right now when working from User:EranBot/Copyright/rc when I want to mark a case as "TP" or "FP" I have to edit the page. I do this by I opening the individual section in a new tab. That way I can move on to the next item on the list while waiting for my edit to get saved. Then I have to go back later and close the tab where I performed the edit. I know there's a script available, but I never installed it. I suspect the script might actually slow things down, because I would have to wait for the page to re-load before I could start to work on the next item. Diannaa (talk) 16:02, 13 May 2016 (UTC)
- This tool doesn't ask you to open anything in a new tab to save state. You might be mistaken. :) -- NKohli (WMF) (talk) 02:25, 14 May 2016 (UTC)
- Right now when working from User:EranBot/Copyright/rc when I want to mark a case as "TP" or "FP" I have to edit the page. I do this by I opening the individual section in a new tab. That way I can move on to the next item on the list while waiting for my edit to get saved. Then I have to go back later and close the tab where I performed the edit. I know there's a script available, but I never installed it. I suspect the script might actually slow things down, because I would have to wait for the page to re-load before I could start to work on the next item. Diannaa (talk) 16:02, 13 May 2016 (UTC)
- Yes, the prototype is in a rough state right now. That was a first pass, to get the back-end architecture started. It'll start looking more like the wireframes over the next couple weeks; I'll give you a heads-up when there's something interesting to look at. :) I'm glad that the wireframes look good to you so far. -- DannyH (WMF) (talk) 16:43, 9 May 2016 (UTC)
- I don't see any issues with what you've got set up so far. Of course I would have to test it out to know for sure. Diannaa (talk) 20:49, 7 May 2016 (UTC)
- Oh, I should have described that better. Clicking the review setting is just one-click. The confirmation box is just if you want to change or cancel the review that you chose. I'm glad this looks good to you so far. -- DannyH (WMF) (talk) 16:22, 5 May 2016 (UTC)
- When one clicks "page fixed", I do not think a confirmation step is desired as this slows down the review process. Doc James (talk · contribs · email) 07:12, 5 May 2016 (UTC)
Difference between this and Earwig's Copyvio Tool?
There is Earwig's Copyvio Tool, which is popular and familiar to many people on English Wikipedia.
Eranbot was originally imagined as a bot which automatically checked everything. It seems that now, it is proposed that a version of Eranbot be easier to any user to direct to check any particular Wikipedia article. That user-controlled version of Eranbot sounds like the Earwig tool.
I am already familiar with the Earwig tool, because it is older and established. I think other people understand the Earwig tool also. Can someone please explain how the user-controlled part of the Eran tool will be different from the Earwig tool? I do not immediately recognize the difference. Blue Rasberry (talk) 17:50, 13 May 2016 (UTC)
- I am interested to hear as well. Casliber (talk) 21:10, 13 May 2016 (UTC)
- Hi @Bluerasberry: could you tell me where's the proposal about a user-controlled version on Eranbot? I'm interested in looking at it. Thanks. -- NKohli (WMF) (talk) 05:43, 14 May 2016 (UTC)
- NKohli (WMF) The "draft wireframes" above is what I was calling the "user controlled version of Eranbot". The version of Eranbot that has been used in the past gives reports automatically and is not interactive. This "draft wireframes" project seems to be able to give reports at the request of users, which seems new to me. Am I misunderstanding something? Eranbot was not controllable by users before, and now in this version above, it outputs reports if the user inputs an article name, right? Blue Rasberry (talk) 01:19, 16 May 2016 (UTC)
- @Bluerasberry: Yeah, you're misunderstanding it. The tool we're working on is exactly the same as Eranbot's existing en:User:EranBot/Copyright/rc page except that it'll be much easier to filter, search, mark pages as Copyright violations and check for plagiarism with inbuilt diffs without users needing to open multiple tabs to check for plagiarism. The input box you see is for filtering by Wikiprojects, which was one of the requested features. We might also in future have an input box for searching for plagiarism history for a given page. There are no on-demand checks. The bot automatically checks every incoming edit if it matches some set threshold criteria. You can play around with the tool (very much a Work-in-progress thing) here: http://tools.wmflabs.org/plagiabot/ The tool will eventually be tied up with your account so you can easily keep a check on edits by certain users or scroll through your marked edits etc. We're open to taking feature requests and suggestions. :) Hope that clears it up. -- NKohli (WMF) (talk) 02:48, 16 May 2016 (UTC)
- NKohli (WMF) I see - so with this Eranbot tool, it is not possible to check whether any particular article includes copyright violations, correct? The tool continues to give alerts, and maybe those alerts can be filtered, but it still will not be possible to get reports for particular articles on request, right? Blue Rasberry (talk) 02:58, 16 May 2016 (UTC)
- @Bluerasberry: Correct. Copyvios can do that for you by comparing the page with sources on Turnitin or using Google/Bing APIs. Eranbot only checks new edits for plagiarism. Every time a large-enough edit is made, it grabs the edit text and searches it for plagiarism across the web. -- NKohli (WMF) (talk) 10:36, 16 May 2016 (UTC)
- NKohli (WMF) I see - so with this Eranbot tool, it is not possible to check whether any particular article includes copyright violations, correct? The tool continues to give alerts, and maybe those alerts can be filtered, but it still will not be possible to get reports for particular articles on request, right? Blue Rasberry (talk) 02:58, 16 May 2016 (UTC)
- @Bluerasberry: Yeah, you're misunderstanding it. The tool we're working on is exactly the same as Eranbot's existing en:User:EranBot/Copyright/rc page except that it'll be much easier to filter, search, mark pages as Copyright violations and check for plagiarism with inbuilt diffs without users needing to open multiple tabs to check for plagiarism. The input box you see is for filtering by Wikiprojects, which was one of the requested features. We might also in future have an input box for searching for plagiarism history for a given page. There are no on-demand checks. The bot automatically checks every incoming edit if it matches some set threshold criteria. You can play around with the tool (very much a Work-in-progress thing) here: http://tools.wmflabs.org/plagiabot/ The tool will eventually be tied up with your account so you can easily keep a check on edits by certain users or scroll through your marked edits etc. We're open to taking feature requests and suggestions. :) Hope that clears it up. -- NKohli (WMF) (talk) 02:48, 16 May 2016 (UTC)
- NKohli (WMF) The "draft wireframes" above is what I was calling the "user controlled version of Eranbot". The version of Eranbot that has been used in the past gives reports automatically and is not interactive. This "draft wireframes" project seems to be able to give reports at the request of users, which seems new to me. Am I misunderstanding something? Eranbot was not controllable by users before, and now in this version above, it outputs reports if the user inputs an article name, right? Blue Rasberry (talk) 01:19, 16 May 2016 (UTC)
Sortable
It would be great if the entries could be sorted by article title or by editor. Ninja Diannaa (talk) 14:29, 21 June 2016 (UTC)
- Hmm, sorting by editor would probably take a while to load, and then you'd have to scroll down really far if you want to find somebody whose username begins with R. Maybe what you'd want here is a search, or a filter. Once we have the WikiProject filter set up, you'll be able to click on the bubbles and get a filter that just shows you the cases from that WikiProject. We could potentially do the same thing with an editor's name, so that you could see all of the cases that person is responsible for. Would that work? -- DannyH (WMF) (talk) 16:21, 21 June 2016 (UTC)
- A search or a filter would definitely work better than sorting :) Thanks for the suggestion. Diannaa (talk) 14:51, 23 June 2016 (UTC)
Draft articles still not indicated as such
Draft articles are still not being indicated as such with the Draft: prefix. In fact I just noticed one case, en:Draft:Boston Landmarks Commission, which is showing up as a redlinked article on the copypatrol report. If this does not get fixed, it means I will have to physically inspect all red-linked entries to confirm whether it's red because it's been deleted or because it's in draft space. Diannaa (talk) 19:59, 29 June 2016 (UTC)
- Diannaa: I'm sorry those are still slipping through. The developer who's working on that ticket was away at Wikimania, and it hasn't been finished yet. It'll be a couple days before it's done, maybe early next week. -- DannyH (WMF) (talk) 20:20, 29 June 2016 (UTC)
- This is now done. Apologies for the delay. -- NKohli (WMF) (talk) 12:51, 5 July 2016 (UTC)
- Related: I believe it would be useful for AFC reviewers to be able to filter this feed by Drafts: namespace. I've interviewed a few of them recently, and they point out that copyvio checking is one of their most common activities, and that workflow isn't well supported. They often have a backlog of 500-1000 articles, so being able to run copyvio checks on their backlog with this tool could really speed up their work. Might want to post to the AFC talkpage and follow up. Jmorgan (WMF) (talk) 20:18, 6 July 2016 (UTC)
- Excellent point! I've worked at AfC so I get this :) I've created a phab here. Thanks MusikAnimal (WMF) (talk) 22:43, 6 July 2016 (UTC)
- This is done and deployed. :) -- NKohli (WMF) (talk) 03:29, 20 July 2016 (UTC)
- Related: I believe it would be useful for AFC reviewers to be able to filter this feed by Drafts: namespace. I've interviewed a few of them recently, and they point out that copyvio checking is one of their most common activities, and that workflow isn't well supported. They often have a backlog of 500-1000 articles, so being able to run copyvio checks on their backlog with this tool could really speed up their work. Might want to post to the AFC talkpage and follow up. Jmorgan (WMF) (talk) 20:18, 6 July 2016 (UTC)
Mark diffs where source won't load
It would be useful to be able to flag diffs where the source didn't load correctly in the interface, making it impossible to compare the wiki content with the source content. Sometimes that seems to be a cookie issue, other times it appears the DOM wasn't successfully parsed. I ran through a half dozen or so of the recent items, and experienced this issue with 3 of them. Flagging (and then removing/filtering out?) diffs that can't be effectively evaluated within the tool will save patrollers time, because they don't have to keep trying to load pages that others have already flagged. Jmorgan (WMF) (talk) 20:24, 6 July 2016 (UTC)
- Hi @Jmorgan (WMF):, you're right, that is a frequently encountered problem. The comparison texts you see comes from Copyvios (example compare link). Copyvios doesn't capture JavaScript rendered content or content in iframes. The problem is we query copyvios for the compare text when the user clicks on the Compare panel button instead of pre-loading it. This means we don't know if fetching the text will error out or not before the link is actually clicked. Also, the database we use right now doesn't store URLs in a way which would make it easy for us to keep track of which ones error out. We'd need to create a separate DB to take care of these. I will file a ticket for this task and hope we come around to doing it sometime in the near future. Thank you for the idea. -- NKohli (WMF) (talk) 05:20, 7 July 2016 (UTC)
- Makes sense. Thanks for the info, NKohli (WMF). Jmorgan (WMF) (talk) 18:56, 7 July 2016 (UTC)
Feedback after my first review
So far I've reviewed one item. I have two pieces of feedback one relatively minor the other one a little more substantive but hopefully easy to address.
My first feedback is to ask the proper way to identify items. I reviewed the first item in the list which was Draft:David Coventry, but that doesn't seem like a proper way of referencing an item. In an on-wiki review it may be sufficient to refer to a link to the draft or article, but in those cases the copyvio reports are probably linked within the article or on the talk page. Given that this is an external tool, I was expecting a ticket number or something similar.
My second comment is that I reviewed the draft and concluded that no action was needed. However, I didn't see a place to add reviewer comments. A quick glance at the entry will show there are a fair number of highlighted phrases with word for word matching. In most cases, this is because the article was talking about a writer and used reviews of the subject book including properly quoted excerpts of reviews.
I would like a place to make this observation for two reasons. I hope there will be another level of review checking to make sure that conclusions are valid, and I wouldn't want a second reviewer spending some time trying to figure out why I accepted an article with some many exact matches. Although it doesn't take long to figure out what's going on in this particular case, I can imagine other cases where the rationale may be more subtle and it would be useful to have a documented. The second, related reason is that if I have occasion to look at this again I don't want to have to re-create my thought process I'd like to see a summary of my conclusions.--Sphilbrick (talk) 00:44, 7 July 2016 (UTC)
- Thank you for your thoughts, @Sphilbrick:. For the first concern, there is a unique ID associated with each record but we don't show it in the interface for we didn't know if it would actually serve any purpose for the reviewer. If you think it is useful, we can show the ID number next to the page title.
- Regarding your second concern: Historically, there have been very very few people working on fixing Copyright problems on the wiki. In fact when we started building this tool we knew of only 2 people who actively worked on these issues. This is why we never thought about having a second level of reviewing. But you're right, it might be helpful when reviewers want to go back and check on their own reviews to see why they made the decisions they did. I'll file a task for this and keep in in the loop. Thank you. -- NKohli (WMF) (talk) 05:38, 7 July 2016 (UTC)
Staying logged in
I don't know whether it is intentional, but I don't stay logged in even when it says I am logged in. If I go some time between actions, and then tried to take an action, I get a message that I'm not logged in even though the button in the upper right-hand corner says I am logged in. I have to log out and log back in again. Not a big deal but I'll be surprised if it's intended.--Sphilbrick (talk) 16:19, 8 July 2016 (UTC)
- This is a known issue that we hope to get around to eventually. Thanks and keep the feedback coming! :) MusikAnimal (WMF) (talk) 17:34, 8 July 2016 (UTC)
- Looks like this has been fixed - I was still logged in today after last logging in yesterday.--Sphilbrick (talk) 13:32, 25 July 2016 (UTC)
- Yeah, we crossed that one off the list. There are some more tweaks and improvements coming up. :) -- DannyH (WMF) (talk) 16:32, 25 July 2016 (UTC)
- Looks like this has been fixed - I was still logged in today after last logging in yesterday.--Sphilbrick (talk) 13:32, 25 July 2016 (UTC)
No highlights means what?
What should we conclude (c.f. Jayce Salloum) when there are "Compare" links but no highlighted text?--Sphilbrick (talk) 15:09, 9 July 2016 (UTC)
- This occasionally happens but I don't know why. What I usually do is take a snippet of likely-looking prose from the diff and perform a Google search on it to locate the source web page. In this instance I found it here. Diannaa (talk) 00:12, 10 July 2016 (UTC)
- Hello, this happens because the source text (right panel) has changed over time but the version that Turnitin has cached still contains some text that is there in the article revision. We don't have a way to access the source url's historic revision which contained the copyvio text. And thus you see no matches because we try to match it with the current source revision. This problem is partly because of Turnitin and we hope to be able to resolve this by switching to a better API in the future. Thanks. -- NKohli (WMF) (talk) 10:40, 11 July 2016 (UTC)
A possible suggestion, contingent on understanding the selection criteria
I'm not entirely sure how the entries in the copypatrol list are chosen. I'll make some inferences, and a suggestion and will be happy to see if my suggestion needs modification if my inferences are far off. The entries clearly depend on a recent edit, as they all include references to a diff with the current date. However the comparison test does not appear to look at simply the diff. It must be looking at more content possibly the entire article.
As illustration Tea Party movement is in the list with a diff that adds an image and a caption. However, the "compare" shows the comparison of text to a blog. The matches exact but hardly surprising as the blog notes that it copied the material from Wikipedia. (In fact it appears the text was added in March 2012).
There may be value in deciding to check the entire article for copyright issues, but I think there may be value in distinguishing matches in the added text from other matches.
My suggestion is that we use color coding to distinguish between matching text for the diff in question versus matching text for other parts of the article.
Under the current configuration we have a link to a particular diff and identification of the editor who made the diff and some information about the editor, yet the comparison may have nothing to do with that particular diff. I don't want to undo that as there may be value in that but I wonder if we could use, say orange for matches of the text in the diff to the source versus blue or some or green or something else for matches of text to a source other than that generated in this diff?
I still feel I'm missing something. None of the diffs seem to be minor. If the system looks at recent edits and then looks for possible copyright issues in the entire article, I would expect some of the diffs to be trivial. It seems that the selection of diffs excludes minor edits or edits below a certain size, yet the copyright comparison is on the entire article. This is puzzling to me can you help me with the understand the selection criteria?--Sphilbrick (talk) 21:02, 9 July 2016 (UTC)
- Hi @Sphilbrick: we use recent edits only. Every new edit which is greater than a certain size (and some other criteria) is tested for plagiarism and then content is then displayed to you. We don't look at the entire article but only the diff content. I am sure I have seen several minor plagiarism records with a line or two copied only.
- Checking the entire article for plagiarism won't work because there are a lot of Wikipedia mirrors around the web and those mirrors copy over the revisions pretty quickly. So you'll see the content of a page is "plagiarized" from a lot of sources when in reality those pages added the content after it was added on the Wikipedia page. -- NKohli (WMF) (talk) 10:45, 11 July 2016 (UTC)
- What you're saying makes perfect sense, except in the example I gave of tea party movement the compare report compared text added in 2012 to a source. In fact it was a false positive because that source had copied material from Wikipedia. The entry contained a death but the diff was unrelated to the material in the compare report. I can't seem to find that entry in the system now. I watch to see if I can find another example.--Sphilbrick (talk) 14:33, 11 July 2016 (UTC)
- Actually, I did find it; I see that it is in the all cases list not the open cases list. It isn't necessarily a big deal but I want you to know, this is an example where there is a recent diff but the compare screen is unrelated to that diff.--Sphilbrick (talk) 14:37, 11 July 2016 (UTC)
- I understand. The blog in this case was essentially a mirror for Wikipedia. We don't yet have a way to filter out mirrors but I will create a ticket for this. Thank you. -- NKohli (WMF) (talk) 16:08, 11 July 2016 (UTC)
- Sorry if it sounds like I'm beating the point to death but I'd like to make sure we're on the same page. I understand the problem with mirrors. However, you said you look at the recent diff so you don't have to worry about mirrors. I accept this. My point is that the material flagged wasn't in the diff, it was a four-year-old edit. If the algorithm is supposed to be searching for copy vios is in the diff, it did something different in this case.--Sphilbrick (talk) 18:31, 11 July 2016 (UTC)
- The diff shows Koavf adding an image with a lengthy caption to the article. The iThenticate report matches the diff, so I'm not too clear what you mean when you say "the material flagged wasn't in the diff". (It's the data in the iThenticate report that triggers the copyvio report, so I always go there when I get confused). Earwig's copyvio tool on the other hand shows a huge overlap with the purported source. There's a couple of clues here: Koavf's edit summary ("This is related because...") kinda implies that he's re-adding this material to the article; someone has removed it for whatever reason, and he's adding it back. And the url for the blog post shows a creation date of October 2015. Checking the article history shows that the content was present in the article already on the first day of October 2015. Using the Wikiblame tool shows Koavf added the image on October 31, 2014 and later amended the caption to what you see today. So this is a case of a user re-adding content that appear in a prior version of the same article and hence is a false positive. Diannaa (talk) 22:11, 11 July 2016 (UTC)
- I agree, the diff relates to the image and caption. The compare report covers extensive material from the blog, which was copied from the article, but not included in the diff. I was told that the system is checking recent diffs, but not the whole article. In this case, the matching material is not in the diff. It is a false positive, but I do not yet know why the compare report looked at material other than the diff. (I haven't been looking at the iThenticate report, I didn't realize that is the trigger - I'll look at it more.)--Sphilbrick (talk) 13:53, 13 July 2016 (UTC)
- The diff shows Koavf adding an image with a lengthy caption to the article. The iThenticate report matches the diff, so I'm not too clear what you mean when you say "the material flagged wasn't in the diff". (It's the data in the iThenticate report that triggers the copyvio report, so I always go there when I get confused). Earwig's copyvio tool on the other hand shows a huge overlap with the purported source. There's a couple of clues here: Koavf's edit summary ("This is related because...") kinda implies that he's re-adding this material to the article; someone has removed it for whatever reason, and he's adding it back. And the url for the blog post shows a creation date of October 2015. Checking the article history shows that the content was present in the article already on the first day of October 2015. Using the Wikiblame tool shows Koavf added the image on October 31, 2014 and later amended the caption to what you see today. So this is a case of a user re-adding content that appear in a prior version of the same article and hence is a false positive. Diannaa (talk) 22:11, 11 July 2016 (UTC)
- Sorry if it sounds like I'm beating the point to death but I'd like to make sure we're on the same page. I understand the problem with mirrors. However, you said you look at the recent diff so you don't have to worry about mirrors. I accept this. My point is that the material flagged wasn't in the diff, it was a four-year-old edit. If the algorithm is supposed to be searching for copy vios is in the diff, it did something different in this case.--Sphilbrick (talk) 18:31, 11 July 2016 (UTC)
- I understand. The blog in this case was essentially a mirror for Wikipedia. We don't yet have a way to filter out mirrors but I will create a ticket for this. Thank you. -- NKohli (WMF) (talk) 16:08, 11 July 2016 (UTC)
Completed items in the archives are not showing as such
I am now working from the https://tools.wmflabs.org/copypatrol page, but in the past I was using the User:EranBot/Copyright/rc pages. What I would typically do is move some items to the archives and work from there, so as to avoid having continuous edit conflicts with the bot. I just discovered that perhaps these items did not get marked as completed at https://tools.wmflabs.org/copypatrol. There's plenty of completed items in archives 17 through 45. The oldest unchecked item (other than the really old stuff from archives 1 through 16) is en:Vajrayana dated 05:05 on June 14. But https://tools.wmflabs.org/copypatrol is showing page after page of unchecked stuff prior to that date, stuff that I actually checked. Diannaa (talk) 01:32, 10 July 2016 (UTC)
- Yes. This is because whatever you marked on the Copyright/rc page is marked on that page only. Those assessments were not sent back to the database and thus, copy patrol has no idea what the assessment for a record was. Possible solutions to this problem include scraping all past pages from Copyright/rc (difficult) or manually marking the assessments (medium) or not showing pages from beyond a certain date (easy). This is still under discussion and will hopefully be resolved soon. In the meantime, you should work only on batches from the time that they have been unchecked. It's being tracked here: phab:T138112. -- NKohli (WMF) (talk) 10:52, 11 July 2016 (UTC)
- Okay, I misunderstood; I thought the Copyright/rc pages were used in preparation of the database. I will amend the blurb at the top of the main Copyright/rc page and ask people not to use it any more and direct them to the tools.wmflabs.org/copypatrol page instead. Diannaa (talk) 20:39, 11 July 2016 (UTC)
Suggestion - a third option "Review in Progress" might be helpful
I'd like to mention two other classes of things that don't quite that into the binary "page fixed" versus "no action needed".
I recently reviewed an article and identified some concerns which I have brought to the attention of the editor. Depending on the response of the editor the article might get deleted, it might get rewritten with the need for revdel of early versions or I might be persuaded that no further action is needed.
I can't choose the "page fixed" option because it hasn't yet been fixed. I can't choose the "no action needed" because I think some action is needed, we just haven't decided exactly what action. I wouldn't want another person coming into the tool, seeing that neither box is checked and starting the effort to do their own review. They might eventually stumble on my post at the editor's talk page but that isn't likely to be the first place they'll check so they will have wasted time. I'd like a box, something along the line of "review in progress", ideally with a date attached and a name so that if another reviewer sees that the issue is still not resolved after a few days, they might well decide to look into this one. It would also be a sign they should probably look at the article or editor talk page to see what if anything has been said.
In a second instance I am almost certain there is a problem, but I nominated it for CSD G 12. Again, neither of the two options presented fit this case yet doing nothing means that another reviewer might decide to take this one on. This one isn't quite as serious as a quick glance at the article will show the CSD nomination, but if they start by reviewing the diff and reviewing the compare reports they might spend some time before realizing they don't need to look at it further. This is another case where "review in progress" might help.--Sphilbrick (talk) 17:49, 10 July 2016 (UTC)
- Hi @Sphilbrick:: Yes, we don't want to waste people's time reviewing a case that someone else is already working on. From the point of view of the other editor, I think all they need is for that case to not appear in the open cases field. The main advantage would be as a reminder for you, so that you'd know to go back to that page and look for responses. Do you think you would need that reminder, or would you use your watchlist for that?
- For the second example, I think adding a speedy deletion template means that the page has been fixed, in the sense that we've moved it into the next phase of that process. I don't think we need to monitor the deletion process and update our records. Does that work? -- DannyH (WMF) (talk) 18:28, 11 July 2016 (UTC)
- If this were the only venue for following up on copyright issues I might want a more formal way of keeping track of tickets to make sure that nothing falls between the cracks but this is not the only way that issues get reviewed so I'd be fine with an option that allows me to click a button and take it out of the list of open entries, and take the responsibility on myself with a watchlist to monitor anything I'm personally reviewing.
- Regarding the second example, I'm fine with marking it as fixed which I will interpret as moving it into the next phase of the process, so yes that works for me.--Sphilbrick (talk) 19:43, 11 July 2016 (UTC)
- That's the way I have been handling them; pages I nominate for deletion are automatically added to my watch-list, and I therefore have a built-in way to follow up on the case to completion. Diannaa (talk) 20:47, 11 July 2016 (UTC)
- Regarding the second example, I'm fine with marking it as fixed which I will interpret as moving it into the next phase of the process, so yes that works for me.--Sphilbrick (talk) 19:43, 11 July 2016 (UTC)
Contributions
Will reviewing via this tool count in my contributions on Meta, like this post? I know it's petty but I like to think I'm always racking up my edit count. This was the one critique I had of Huggle where I was reviewing editor conduct but the reviews themselves weren't counted, only the actions in en-wp which were triggered by reviewing. Otherwise this is an awesome tool. Chris Troutman (talk) 22:46, 14 July 2016 (UTC)
- @Chris troutman: Not for the reviews themselves, no. You will however show up on the leaderboard! Eventually we hope to add some semiautomated features like rollback, CSD tagging and issuing of user talk page templates. Rest assured either way your efforts won't go unnoticed :) MusikAnimal (WMF) (talk) 00:06, 15 July 2016 (UTC)
- I hadn't realized there was a leaderboard. Consider expanding it to top 10, otherwise, it won't be long before new participants have no way to appear on the board in any reasonable amount of time. Obviously, leaderboards have their own potential for abuse, but if not abused, can be a fun way to encourage involvement.--Sphilbrick (talk) 12:11, 16 July 2016 (UTC)
- Thanks for expanding it to 10.--Sphilbrick (talk) 11:08, 18 August 2016 (UTC)
- I hadn't realized there was a leaderboard. Consider expanding it to top 10, otherwise, it won't be long before new participants have no way to appear on the board in any reasonable amount of time. Obviously, leaderboards have their own potential for abuse, but if not abused, can be a fun way to encourage involvement.--Sphilbrick (talk) 12:11, 16 July 2016 (UTC)
Use EranBot on frwiki
Hi,
Actually on French Wikipedia find copyvios is not easy, we need to check if an added text is somewhere else on internet by copy it and search on Google some suspect sentences. It's a long work and impossible to check all added content on the evening rush time.
I am very interested to adapt the plagiarism detection bot to the French Wikipedia. Do you prefer to centralize in one labs tool project all the instances or separate peer language ?
Have a nice day --Framawiki (talk) 16:09, 26 July 2016 (UTC)
- Hello Framawiki! We would love to help with plagiarism detection on the French Wikipedia. First, to be clear, Community Tech authored CopyPatrol which is a web interface showing data provided by EranBot. EranBot scans recent changes and compares it with Turnitin, a plagiarism detection service. I did some quick research and it appears a French edition of Turnitin exists, which is promising. I should mention we also have hopes to eventually use Google instead of Turnitin, in which case we could simply configure it to search for French results, but it's unclear when that effort will begin. So for now I can't give you a definite answer on feasibility, but your request has been noted and we will happily investigate further and keep you updated with our findings. Regards MusikAnimal (WMF) (talk) 17:16, 26 July 2016 (UTC)
- Is there any reason why we should not use both? My naive understanding is that iThenticate is good for checking against newspapers, academic journals, e-books and other things that may be behind paywalls, while Google is better for the wider internet. MER-C (talk) 08:54, 27 July 2016 (UTC)
Small process suggestion
The impact is this suggestion is small, but I think the effort to implement it will be very small, so I hope it is worth considering.
When I review an item, I always open the iThenticate report, a diff and the Compare option. When I am done, I need to close all three. I don't know how the system could handle closing the report or the diff, but I can imagine it could easily close the Compare report. So my suggestion:
When a user clicks any of the buttons in the upper right of the entry, that action should also close the Compare report.
Obviously, if other users, especially Diannaa, would not find this helpful, I'll withdraw support.--Sphilbrick (talk) 16:21, 30 July 2016 (UTC)
- I am not using the Compare reports at all, as they don't function very well on my laptop. They are way too small - 5 inches by 2 and 5/8 inches. I find scrolling through to find the matches to be too time consuming. So I use Earwig's tool. Normally I open the diff, the history, and the iThenticate report (if needed - sometimes obvious copyvio is obvious), and then select a likely-looking source url and plug it into Earwig's tool. If the edit has already been removed I plug in the diff number as well. If the url I select to compare does not show a match, I google a snippet of the prose to locate the source. Diannaa (talk) 00:54, 1 August 2016 (UTC)
- Sphilbrick, that's a good suggestion that hadn't occurred to us -- we'll talk about it, and see what we can do. Diannaa, I'm sorry to hear that the compare panels aren't helping you. Are there any changes we could make to the interface that would make your workflow easier? -- DannyH (WMF) (talk) 22:09, 1 August 2016 (UTC)
- No, I am working pretty fast already. If I think of anything I will let you know. Thanks, Diannaa (talk) 22:12, 1 August 2016 (UTC)
- Sphilbrick, that's a good suggestion that hadn't occurred to us -- we'll talk about it, and see what we can do. Diannaa, I'm sorry to hear that the compare panels aren't helping you. Are there any changes we could make to the interface that would make your workflow easier? -- DannyH (WMF) (talk) 22:09, 1 August 2016 (UTC)
- I've noticed that my workflow is changing over time. In an odd coincidence, after posting my suggestion, I wondered about Diannaa's workflow, and mused about the possibility that she wasn't using the Compare reports. I worked on some today, and found that I could work well without them. I haven't been using Earwig's tool, will consider that. If Diannaa isn't using the Compare panels, and I stop using them, then your follow up question about possible changes becomes important. Like Diannaa, I don't have any immediate suggestions but will try to keep it in mind as I work on more.--Sphilbrick (talk) 13:45, 3 August 2016 (UTC)
- Hmm, that's interesting. Can you say what there is about the compare panels that doesn't feel right? We're considering a couple possible changes, and it would be great to have your input. Also, if you're not using the compare panels or Earwig's tool, are you using the iThenticate report, or something else? -- DannyH (WMF) (talk) 17:06, 3 August 2016 (UTC)
- @Diannaa: I understand the compare panels are appear too small on your machine, but I thought I'd still let you know that we've just deployed a feature to auto-scroll to matches within the comparison pane. Hopefully this helps! :) MusikAnimal (WMF) (talk) 22:10, 3 August 2016 (UTC)
- Thanks, I'll have a look at that :) -- Diannaa (talk) 22:12, 3 August 2016 (UTC)
- @Diannaa: I understand the compare panels are appear too small on your machine, but I thought I'd still let you know that we've just deployed a feature to auto-scroll to matches within the comparison pane. Hopefully this helps! :) MusikAnimal (WMF) (talk) 22:10, 3 August 2016 (UTC)
Link to Whitelist
Can we provide a link to the Whitelist somewhere here? This link is this one [1]
Also can we get the number of open cases displayed somewhere? Doc James (talk · contribs · email) 20:16, 9 August 2016 (UTC)
- We were just talking about whitelists today, actually. :) We're going to add a whitelist for users, as Diannaa asked for a little while ago. I posted on that ticket -- we'll figure out where to put links for both whitelists.
- The number of open cases is a good idea -- we'll think about where that could go. -- DannyH (WMF) (talk) 20:57, 9 August 2016 (UTC)
- Number of open cases will not be accurate, because prior to June 2016 I was working from the listings at User:EranBot/Copyright/rc, and the data has not (as far as I know) been transferred over to https://tools.wmflabs.org/copypatrol. Diannaa (talk) 01:19, 13 August 2016 (UTC)
- Yes but the number of cases listed here would still be useful. Are you know working off this new tools list? Doc James (talk · contribs · email) 01:32, 13 August 2016 (UTC)
- Yes; I switched on June 21. Diannaa (talk) 22:05, 14 August 2016 (UTC)
- Yes but the number of cases listed here would still be useful. Are you know working off this new tools list? Doc James (talk · contribs · email) 01:32, 13 August 2016 (UTC)
- Number of open cases will not be accurate, because prior to June 2016 I was working from the listings at User:EranBot/Copyright/rc, and the data has not (as far as I know) been transferred over to https://tools.wmflabs.org/copypatrol. Diannaa (talk) 01:19, 13 August 2016 (UTC)
- I'd rather keep the whitelist hidden from the interface, but it is linked to in the documentation. MusikAnimal (WMF) (talk) 18:25, 17 August 2016 (UTC)
Leaderboard
Can we increase it to 10 or 20? Doc James (talk · contribs · email) 21:32, 15 August 2016 (UTC)
- Yes, I think there's enough activity now to expand to 10. We were just discussing that today. :) It'll happen pretty soon. -- DannyH (WMF) (talk) 23:13, 15 August 2016 (UTC)
- I've updated it to show the top 10. The "last 7 days" column isn't always going to look great, but maybe when less than 10 are shown it will motivate viewers to participate MusikAnimal (WMF) (talk) 04:33, 18 August 2016 (UTC)
User whitelist
@Diannaa, Doc James, MER-C, and Sphilbrick: We have just deployed the user whitelist, which will hide edits by the listed users. I imagine there are a few users right off the bat you probably want to add, so feel free to do so, using the syntax * [[User:Example]] (one per line). The whitelist is cached within CopyPatrol, so after you add someone you may have to wait up to 2 hours before edits by that user are hidden. Let us know if you have questions/concerns/etc. Regards, MusikAnimal (WMF) (talk) 18:23, 17 August 2016 (UTC)
- Wonderful thank you :-) Doc James (talk · contribs · email) 18:26, 17 August 2016 (UTC)
- Good idea, a couple of those names I have seen a lot.--Sphilbrick (talk) 21:33, 17 August 2016 (UTC)
- Coren Bot's wihitelist is here, if it makes sense to move the active users over. Crow (talk) 20:41, 27 August 2016 (UTC)
- Only if they are frequently and falsely triggering this bot should they be added here IMO. Doc James (talk · contribs · email) 21:00, 27 August 2016 (UTC)
- Amost all of those names are not ones I have been seeing. Some of them are no longer actively editing. Better to just add them (super selectively) as we go along, in my opinion. Diannaa (talk) 21:36, 27 August 2016 (UTC)
Searching on diffs when the diff isn't so diff...
From the docs and this page, it appears that the bot searches on the diff text when edits are above a certain amount. One quirk I've noticed in mediawiki is that sometimes when editing headings and reference text, it causes enough of a shift in physical position of the text that the diff shows a lot more having been changed than actually was. As an example, this one that was listed on the cp page. The editor added some spaces and other formatting, but the diff ended up being huge. Not sure of any way to address that here, but it does seem like it will lead to a lot of FPs... Crow (talk) 22:36, 27 August 2016 (UTC)
- Yes exactly. We would need the diff generator to improve to solve this issue. Not really something this bit of software can fix. Doc James (talk · contribs · email) 23:45, 27 August 2016 (UTC)
- Other than that, my initial experience with the tool is extremely positive. Well done team! Crow (talk) 01:13, 28 August 2016 (UTC)
- Yes exactly. We would need the diff generator to improve to solve this issue. Not really something this bit of software can fix. Doc James (talk · contribs · email) 23:45, 27 August 2016 (UTC)
Monitoring rationales
(This is partly a follow-up to my previous post but it's a different point so I'm making it a separate section)
I assume some thought has been given to compiling statistics of the results. The most basic statistic is to keep a count of number of instances resulting in a page fixed versus number of instances where no action is needed. However, I suggest this second statistic is close to useless. I briefly reviewed some of the closed cases and looked at instances where no action was needed. In some cases, no action was needed because there was a false positive, i.e. the tool identified a match but there was some reason why this match was acceptable and nothing needed to be done. In other cases, there was no action needed because the page was deleted for other reasons.
Knowing how often the tool generates false positives ought to be of some interest to the creators of the tool but note that the "no action needed" captures false positives as well as some other things that are not necessarily false positives. I think it would be useful in the case of a "no action needed" to keep track of the reason. In my previous feedback I had suggested a free-form field for the reviewer to add some comments, but I'm now thinking that this should be a free-form field as well as a number of checkboxes to allow the reviewer to categorize the review. At a minimum, the option should be three.
No action needed because:
- False Positive
- Page removed for other reasons
- Other (Please explain __________)
I can't think of anything that would fall into the third category at the moment but it's always useful to have a catchall.
If the options were limited to these three, one would be able to run a simple study to monitor the proportion of false positives.
I think it is useful to go further, although it may be useful to proceed in baby steps. For example, rather than simply a single entry for false positive, I might want to distinguish between false positives because the source material is properly licensed versus false positives because the bulk of the matching material is properly quoted, versus false positives because in the judgment of the reviewer the matching phrases do not reach the level of a copyright violation.--Sphilbrick (talk) 10:48, 7 July 2016 (UTC)
I just noticed that the "no action needed" button has text suggesting that it means there was a false positive. As noted, one reason for clicking the "no action needed" button is that the page has already been deleted, which is not necessarily (and probably not) a false positive. It occurs to me that if there is some difficulty implementing my suggestion to keep track of the reason as a pop up box to be filled by the reviewer, another option is to change from two buttons to three buttons:
- Page Fixed
- No action needed - false positive
- No action needed - page has been removed for other reasons
That would allow you to keep track of true false positives with less work than creating the options I suggested.--Sphilbrick (talk) 10:55, 7 July 2016 (UTC)
- All excellent points! We are currently working on phab:T134289 so that the tool will automatically mark deleted pages as "no action needed". So that much we shouldn't have to worry about. I do like your idea for categorization, if not for statistics, just to review others' reviews and see why they chose said action. Based on your suggestions, I'm thinking if you click on "no action needed", a modal pops up with the radio buttons: "False positive", "Content is properly licensed", "Content is properly quoted", "Other (please explain)" and maybe other options if we can come up with good ones. "False positive" I think would be analogous to "sufficiently paraphrased". How does that sound as a start? MusikAnimal (WMF) (talk) 19:47, 7 July 2016 (UTC)
- Regarding auto marking of deleted pages - I like that. Regarding the radio button choices, that sounds like a great start.--Sphilbrick (talk) 00:46, 8 July 2016 (UTC)
- Types of false positives I have encountered include: properly attributed copying of licensed or PD material; properly attributed quotations; restoring material from a previous revision of the same article; addition of tables; addition of lists; addition of timelines; addition of math symbols; additions to bibliographies. Moving material around within the article can trigger a false positive, even if the move is done within the same edit. Diannaa (talk) 13:26, 8 July 2016 (UTC)
- Regarding auto marking of deleted pages - I like that. Regarding the radio button choices, that sounds like a great start.--Sphilbrick (talk) 00:46, 8 July 2016 (UTC)
- I think there's a few different ideas expressed here for the goal of this feature.
- People working on improving the bot would have more detailed information about how it should be improved.
- People could check on each other's reviews, to make sure they're reviewing properly.
- People could learn more about how to review -- what counts as something to be fixed, vs no action needed.
- I'm not sure that the suggested feature is the best way to achieve those goals. Clicking/filling out a form may not be a huge drag on people's time, but it is a noticeable drag -- so the goal we're trying to achieve should be important enough to justify an extra burden on every review that people work on.
- For the first goal, I don't think people who want to improve the bot need exact statistics in order to make those improvements. If we want to make improvements to reduce false positives, then we'll need to look at the list of examples that Diannaa listed above, and figure out how easy/hard it would be to detect and fix. Off the top of my head, detecting a list is probably easier than checking previous revisions, and less of a performance drag. Knowing that list-related false positives happen 5% of the time and restoring material from a previous revision happens 8% of the time wouldn't really factor into that discussion. The only time that would matter is if a certain type of false positive comes up 85% of the time -- and if there is one, then Diannaa could probably tell us which that is, without extra stats. :)
- For the second goal: I don't think it's realistic that people will want to spend a lot of time checking each other's reviews. There are hundreds of new cases a day, and our goal right now is to get enough people involved that we can actually clear out all the cases. I don't want to encourage people to re-check other people's reviews, when they could be spending that time doing their own reviews. If this tool gets so popular that we start to see bad actors/vandals making deliberately bad reviews, then we might handle that by throttling brand new people, maybe letting them check three cases before an experienced person has to come in and review.
- The third goal is very important -- teaching people how to do good reviews -- and we need to do something about that. But I think the answer there is likely to be a documentation page with instructions, templates, tips, and things to look out for. We don't need to make every review into an example; we just need a helpful page of examples.
- Are there other goals that I haven't picked up on yet? -- DannyH (WMF) (talk) 21:03, 8 July 2016 (UTC)
- These sound like good goals to me. You make great points on why we don't really need to classify reviews, but I don't think with good UI design providing options would slow them down too much. A diligent reviewer is already spending a fair amount of time, and this is essentially just one extra click. Once you get used to the options you'd likely speed through it quickly (unless they decide to go with the "Other" and manually specify rationale). I do realize this is not a critical feature and may not be very popular with all of our users.For checking on other reviews, I agree we probably won't see this much unless something comes up where we are concerned a particular user is not properly doing reviews, or properly correcting the copyright violations as they claim to be. Reviewing the Quarry results of users, all but two of them (three if you include Danny's enwiki account :) have additional user rights, namely "pending changes reviewer". Users with that user right are expected to know what copyright violations are and how to deal with them (see Wikipedia:Reviewing), so if it comes down to it we might consider restricting usage of the tool to these qualified users. This may be more sensible when we add undo/template features that will in turn attract a whole new audience of users. One step at a time! :)Finally, I really like your ideas regarding educating users. I was thinking if it's their first time using CopyPatrol (they have no reviews), we can pop up a modal with basic info on how to use the tool, along with some info on correctly identifying copyright violations (make sure the copied content isn't a compatible license, it's not a properly attributed quote, etc.). MusikAnimal (WMF) (talk) 22:55, 8 July 2016 (UTC)
- I think there's a few different ideas expressed here for the goal of this feature.
- I thought Diannaa was trying to be helpful when adding to the list of false positives. However, I did not interpret her list as a suggestion that a radio button list should include all those options. I concur with DannyH that making it too complex will be counter-productive. I'll obviously let her speak for herself, but I would be in favor of radio buttons with a limited number of options, plus possibly a catch-all "Other". We don't need an exhaustive list of all the ways something can be a false positive, we ought to concentrate on items that might be useful for a reviewer or as part of a teaching or learning environment. I'll give "Content is properly licensed" as a good example. Suppose the article text is a loose paraphrase of the source. It can take some time to think through whether the paraphrase is too close or not, but if the source is licensed. you know not to waste that time. In addition, the license is often not in an obvious location, but seeing that option checked means that if you are training someone, or learning on your own, or reviewing someone else, you don't waste time on the text comparison, you go looking for the license, and confirm it is an allowable license.
- I also agree with DannyH that this feels like drinking from a firehose, so it may seem odd to suggest processes to make it easier for a second reviewer. We need more first reviewers, we hardly should be pushing for second reviewers. However, I am not contemplating a 100% second review, I am suggesting process changes that would make it easier to do spot checks, and would help build mechanism useful in the future for a teaching or learning environment.--Sphilbrick (talk) 16:54, 9 July 2016 (UTC)
- Personally, I like the simple workflow and UI of the current interface. If we add too many bells and whistles it will become intimidating for new reviewers and slow down current users. Also, what would we actually use this additional data for? Unless there is a specific need for it, I'm skeptical that it will ever actually be used for anything. Kaldari (talk) 01:15, 22 September 2016 (UTC)
- I also agree with DannyH that this feels like drinking from a firehose, so it may seem odd to suggest processes to make it easier for a second reviewer. We need more first reviewers, we hardly should be pushing for second reviewers. However, I am not contemplating a 100% second review, I am suggesting process changes that would make it easier to do spot checks, and would help build mechanism useful in the future for a teaching or learning environment.--Sphilbrick (talk) 16:54, 9 July 2016 (UTC)
Dealing with items already nominated - how to handle most efficently
I would like to share a common experience for two reasons.
First, I have a proposal for a tweak to the system but I fear it will be nontrivial.
Second, it is very possible that I simply need to change my workflow, so I'm looking for feedback from other experienced users (looking at you Diannaa) who may be able to share a better way of approaching the workflow.
I use two screens, open the iThenticate report in the right-hand screen and the diff in the left-hand screen. I glance at both to identify the relevant language, then go to the Match overview side of the iThenticate report to open the identified source. In many cases, opening that URL fails, sometimes delivering a 404, sometimes a different error message and I think sometimes a relevant page but not the one with the text. This is typically just a minor bump in the road, and I grab a snippet of text and do a Google search. Sometimes that is immediately successful, sometimes it takes a couple tries to find the right site. I then do the diligence making sure the text is matching, isn't in quotes or a block quote and making sure the source is not freely licensed.
When I'm certain we have an issue, I then returned to the diff, Click on view history to see if I am looking at the most recent diff, and on many occasions find out that the article has already been nominated for G12. On the one hand, it is gratifying that our editors are on top of recent edits so quickly. On the other hand I spent a fair amount of time that is wasted because I didn't realize it had already been nominated.
My simple suggestion is that it would be nice if the report could let us know whether the diff in question is the most recent diff. While a more ambitious request would be an indicator that the article has been proposed for deletion or the edit has already been reverted, at this time I'd be happy just knowing that I ought to be looking at the history to see what has happened subsequent to this diff. My concern is that you are going to tell me that the system looks at recent edits and generates an addition to the report when it finds a match but the addition to the report occurs at the time the diff is the most recent diff. Thus, by definition, when it is added to the report there is no subsequent edit and my request effectively asked that the system continuously monitor the article and update itself when there are subsequent edits. That may be unreasonable.
One alternative workflow is that after viewing the diff I should always look at the view history before proceeding. I might try that but while the circumstance I outlined is common it is still only a minority of the situation so I may be wasting time in a different way. As I said, I'd be interested in feedback from others in case they've found an efficient way to address the situation.--Sphilbrick (talk) 12:26, 29 August 2016 (UTC)
- Yes would be good to know if the edit was already reverted. Still one would likely want to check it though. Doc James (talk · contribs · email) 12:36, 29 August 2016 (UTC)
- We should be able to check if it is the most recent edit pretty easily, but whether or not it has been reverted I believe isn't as straightforward. For example, there could be cherry-picking, where another editor manually removed or reworded the change containing the copyright violation. I think we could also check if the page is in Category:Candidates for speedy deletion as copyright violations and indicate this somehow. MusikAnimal (WMF) (talk) 03:43, 30 August 2016 (UTC)
- @ User:Sphilbrick: Since I am working from the bottom of the queue, i.e. yesterday's reports, I seldom encounter pages that are tagged as G12; they are normally deleted in the first 24 hrs and are therefore already gone when I start work for the day. I find the edit in question is almost never the top edit, as at a minimum the page has often been visited by Yobot to remove invisible unicode characters, which are likely introduced as an artifact of the copy-paste. I normally open the diff and the history right off. I usually read (or skim) the diff and look at the history before I start assessing anything. I like to examine the recent history to get a sense of whether there's just the one edit that needs to be examined, or whether there's been a heap of copyvio and promotional stuff being added over the previous few days or weeks before I start. Diannaa (talk) 22:53, 1 September 2016 (UTC)
Error message
I am getting an error message when I try to load https://tools.wmflabs.org/copypatrol. "Slim Application Error" - Diannaa (talk) 13:13, 18 September 2016 (UTC)
- Fixed now Diannaa (talk) 18:27, 18 September 2016 (UTC)
- Not fixed now.--Sphilbrick (talk) 18:09, 1 November 2016 (UTC)
- Hi Sphilbrick, I just tried to load the page, and it works for me. Are you still getting the error? DannyH (WMF) (talk) 20:24, 1 November 2016 (UTC)
- It may be related, or may not, but there are a handful of errors every day at the moment about users not having the
$_SERVER['HTTP_ACCEPT_LANGUAGE']variable set. I'm not sure how this would arise, but actually it seems that that bit of code is old and no longer required; I've incorporated a fix in the multiwiki branch. — Sam Wilson ( Talk • Contribs ) … 02:18, 3 November 2016 (UTC)
- It may be related, or may not, but there are a handful of errors every day at the moment about users not having the
- Hi Sphilbrick, I just tried to load the page, and it works for me. Are you still getting the error? DannyH (WMF) (talk) 20:24, 1 November 2016 (UTC)
- Not fixed now.--Sphilbrick (talk) 18:09, 1 November 2016 (UTC)
I am again today getting an error message when I try to load https://tools.wmflabs.org/copypatrol. "Slim Application Error". Diannaa (talk) 15:10, 16 November 2016 (UTC)
Listings all wrong today
Not sure what happened, but today the listings are all wrong. Consider the first in the Open queue on enwiki as of now, Iolo Morganwg. The diff points to an edit to Ralstonia gilardii from May, and the Iolo article itself hasn't been edited in weeks despite the diff stating it was from today. Crow (talk) 17:34, 16 November 2016 (UTC)
- Integer overflow on the bot? Yesterday the recorded diffs were in the 750xxxxxx range, today they're in the 130xxxxxx.... Crow (talk) 18:14, 16 November 2016 (UTC)
- Sorry! French Wikipedia records were showing up on the English version. This has been fixed :) That was part of a big deploy that has other bugs we are working to fix. E.g. the review buttons stay in the loading state, but they are being recorded. Hopefully everything will be stable soon. Sorry for the inconvenience! MusikAnimal (WMF) (talk) 03:29, 17 November 2016 (UTC)
- There's been no new reports for 24 hours. Any news on how soon we can expect normal activity to resume? Thanks, Diannaa (talk) 21:17, 17 November 2016 (UTC)
- I believe we've stabilized EranBot and activity should be back to normal. There's still that annoying bug with the review buttons... However mind you that your reviews are being recorded, even though it may appear they are not. You can verify this by checking the "Reviewed cases". Apologies again for the inconvenience! MusikAnimal (WMF) (talk) 21:10, 18 November 2016 (UTC)
- There's been no new reports for 24 hours. Any news on how soon we can expect normal activity to resume? Thanks, Diannaa (talk) 21:17, 17 November 2016 (UTC)
- Sorry! French Wikipedia records were showing up on the English version. This has been fixed :) That was part of a big deploy that has other bugs we are working to fix. E.g. the review buttons stay in the loading state, but they are being recorded. Hopefully everything will be stable soon. Sorry for the inconvenience! MusikAnimal (WMF) (talk) 03:29, 17 November 2016 (UTC)